Claude Code 就是你已有的 OpenClaw 替代品
原文:https://every.to/source-code/claude-code-is-the-openclaw-alternative-you-already-have
OpenClaw 向世界展示了 AI 助手可以是什么样子。
这个开源项目在短短 60 天内成为了史上获得最多星标的软件项目——不是因为炒作。人们体验到的是不只是回答问题、而是真正"做事情"的 AI:管理日历、发送邮件、操控浏览器。所有这些只需在 WhatsApp 或 Slack 里发一条文字消息就能触发。
我眼看着 Sam Altman 聘请了 OpenClaw 的创作者,微软 CEO Satya Nadella 在这个框架上构建了"ClawPilot"。而整个过程里,一个念头始终让我耿耿于怀:Claude Code 早就做到所有这些了。这些甲壳类动物到底有什么特别的?
答案在于公众认知。OpenClaw 被宣传为 AI 代理(AI Agent),而 Claude Code 被宣传为编程工具。
我们在 Every 公司基于 Claude Code 和 OpenClaw 开发了数月——包括 Claudie,一个负责我们咨询团队后台运营的 AI 员工。这段经历让我们看清了为什么人们对 OpenClaw 最初的兴奋正在降温——这与其不可靠性有关——以及为什么 Claude Code 是当今构建 AI 助手最强大的平台。
如果你想构建一个能真正做事的 AI,不需要等待更好的 OpenClaw 替代品,因为你已经有了。下面就是核心理由,以及使用方法。
驾驭模型
Claude Code 能做到所有让 OpenClaw 走红的事情:使用工具、管理文件、独立运行数小时。这不是巧合,因为在底层,两者本质上是同一件事:AI 模型的驾驭工具(harness)。
把 Claude、GPT、Gemini 这些 AI 模型想象成强壮有力的骏马。驾驭工具就是让你能够引导这些马力的东西。它是位于原始 AI 模型和你试图完成的任务之间的软件层,决定模型如何接收上下文、可以使用哪些工具、如何在对话间记住信息、以及如何与外部世界通信。
你早就在使用驾驭工具了:ChatGPT 将模型封装在一个可以浏览网页、运行代码的聊天界面里;Cursor 将模型封装在代码编辑器里。Claude Code 则提供了一种更开放的方式:调用工具、将步骤串联起来、朝着一个目标自主工作。这正是 OpenClaw 所做的。
 AI 模型就像强壮有力的骏马,驾驭工具则让你能够引导这些马力。(图片由 Nityesh Agarwal 提供)
AI 模型就像强壮有力的骏马,驾驭工具则让你能够引导这些马力。(图片由 Nityesh Agarwal 提供)
人们喜爱 OpenClaw 的什么——以及 Claude Code 如何做到同样的
OpenClaw 之所以走红,是因为它让人们突然"懂了"些什么。第一次,很多人看到 AI 离开对话窗口、去完整执行一项任务。各类评测和讨论中诞生了一个非官方标语:真正做事的 AI。这种能力可以分解为五个类别——Claude Code 每一个都具备。
1. 它像一个真正的人。
OpenClaw 随时随地跟着你——它记得你昨天在工作什么、知道你日历上有什么安排、掌握着你的工作上下文。
这种感觉跟用哪个聊天应用——Telegram、Slack 还是 iMessage——来跟它沟通关系不大。真正的原因在于代理能看到多广的工作和生活范围。因为 OpenClaw 从你的用户根目录启动运行,它可以读取你电脑里的每一份笔记、每一个文件和文件夹,带给它一个员工才有的上下文广度。
大多数人不知道 Claude Code 能做到同样的事。他们只在单一项目文件夹里运行它,于是它感觉像是个编程工具——但那只是人们给它的有限上下文造成的错觉。
这个问题很容易解决。给 Claude Code 访问整台电脑的权限,现在你就有了一个"AI 员工"。
默认情况下,Claude Code 在每个动作前都会征求你的许可,而 OpenClaw 不会。当你在做专业工作时,这是一种审慎的默认设置。但如果你希望它有更多自主权,可以加上 --dangerously-skip-permissions 标志。
2. 它在真实世界做事。
OpenClaw 的用户都能讲出一个神奇的"顿悟时刻"——亲眼看到它行动起来的瞬间。给它发一条消息,醒来就看到一个集成了支付功能的可用网站。让它整晚整理收件箱,早晨就发现草稿已等候在那。
同样,Claude Code 可以直接操作你的电脑——创建和移动文件、运行程序、读取网页。而且两个工具都可以通过模型上下文协议(Model Context Protocol,简称 MCP,是 Anthropic 引入的一项开放标准)接入外部服务——Google Workspace、CRM、Asana、日历、数据库。
3. 它会记住(差不多吧)。
人们发现 OpenClaw 可以做长期记忆。今天存一条笔记,一个月后问它——"我最近读了什么关于 X 的东西?"——它不只返回那条笔记,还会翻出你自己都忘了写过的相关内容。
Claude Code 的记忆能力更精细。它存在于三个层面:
- 一个叫 CLAUDE.md 的文件。 它存放在你运行 Claude Code 的任意文件夹里,你来写进代理应该知道的所有内容。它在每次启动时都会读取这个文件。这是纯文本文件,你可以在任何编辑器里修改。
- 内置的记忆系统。 代理工作时会保存有用的观察结果,后面再调出来使用。这是 Claude Code 原生自带的功能,无需任何设置。
- 本地搜索引擎。 在构建 Claudie 时,我加入了 qmd——一个开源工具,能把机器上的所有对话日志、会议记录和工作文档索引化,让她能跨所有内容进行搜索。
4. 你可以教它新技能。
OpenClaw 允许你教它新把戏:写一个简单的文本来描述你想让它处理的任务——即"技能"(skill)——代理就会拾取并遵循它。在 Every,我们有做品牌一致幻灯片的技能、管理客户看板的技能、以及在 Asana 里做项目管理的技能。
技能是 Anthropic 的标准规范,这意味着 Claude Code 内置了相同的系统。为 OpenClaw 写的技能直接就能在 Claude Code 里运行,完全不需要改动。
5. 它自己运行,你在睡觉时它也在工作。
OpenClaw 的标志性功能叫心跳(heartbeat)——一个每分钟运行一次、判断需要做什么然后就去做的过程。早上六点,你还没打开手机,它已经读了整夜的邮件、扫描了日历、草拟了每日简报、为需要回复的消息排好了回信。
在底层,心跳就是一个 cron 任务。Cron 是自 1970 年代以来就内置在 Mac 和 Linux 操作系统里的软件,它只做一件事:按时间表运行一段代码。可以是每分钟、每整点、或每周一早上六点。
Claude Code 可以接入同一个系统。它有一个模式(叫"headless"——无头模式),接收一个任务后独立运行,不需要你坐在电脑前。把这个跟 cron 结合起来,你就有了在你睡觉时工作的 AI。连 OpenClaw 的创作者 Peter Steinberger 本人 都说过,把 Claude Code 加上 cron 任务的配置就等于 OpenClaw。
OpenClaw 的问题出在哪
我们已经确认 OpenClaw 和 Claude Code 能完成许多相同的事。那我为什么还是引导大家去用 Claude Code?有几个原因。
先让我把该给的肯定给到:OpenClaw 向世界展示了一件重要的事情,它也完全配得上那 38 万个 GitHub 星标。但当我去深入代码库后,我发现了一个复杂到制造出比解决的问题还多的架构。
会话问题
OpenClaw 会为每个用户维持一个尽可能长的单一会话。你白天发的每一条消息都落进同一个会话里,上下文越积越多。如果你用 OpenClaw 做很多任务,到了中午,会话可能承载超过 50,000 个 token——大约是一份长文档的文字量。系统理应在每天凌晨四点重置,但这个操作不可靠。所以你可能早上只打了声"hi",却被按 50,000 个 token 计费——用 GPT 5.5 或 Opus 4.8 大概要花 0.25 美元——因为系统没有重新开始,而是继续了昨天那个膨胀的会话。
Mike Taylor,我们团队里的一位同事,他用过我们基于 OpenClaw 构建的 Plus One AI 助手,就碰到了这个问题。他检查了日志,发现一个从第一天起就没断过的无尽会话。每发一条消息都在消耗大量 token,因为全部都挤在一个巨大的会话里。
在 Slack 上跑 Claude Code 时,工作方式就不同了:一个话题串就是一个会话。开一个新话题串,得到一个干净的上下文窗口。每个会话启动时只载入基线指令和你的 CLAUDE.md 文件——这是你为它写的常驻上下文,通常只有 2,000 到 5,000 个 token,而不是 50,000。当某个话题串确实变得过长需要压缩时——这个过程叫 compaction,系统会压缩更早的对话历史为新信息腾出空间——Claude 会自动做裁剪。
记忆问题
OpenClaw 的记忆系统是精心设计的。它的构建目标是在对话间记住细节,这样代理不会在你每次发消息时都从零开始。为了实现这一点,它运行着:
- 八个独立的引导文件(bootstrap files),即它初次启动时写入的文件,每份存储关于你不同种类的信息,包括 AGENTS.md、SOUL.md、TOOLS.md、IDENTITY.md、USER.md、HEARTBEAT.md、BOOTSTRAP.md 和 MEMORY.md
- 一个记忆整合的"做梦"(dreaming)过程,它会复盘当天发生的所有事情,决定哪些值得保留、哪些可以遗忘
- 多种搜索方式
- 一个存储层,以类似个人维基百科的方式组织它知道的事情,每条记录都附有证据
作为一名工程师,我能理解为什么他们会这样构建,但作为用户,这种精巧是有代价的。
当 OpenClaw 犯了错——忘记重要信息,或是基于过时信息行动——答案可能散布在六七个地方:引导文件、每日笔记、做梦过程、旧笔记的压缩版本、系统清空短期记忆时保存的内容、或仓储式的存储层。很多时候,你根本判断不了问题出在哪,这让根本原因无法被诊断。
换句话说,这种复杂性把调试从"改进系统"变成了"猜谜游戏"。
相比之下,Claude Code 的记忆存储在普通的 Markdown 文件里。当 AI 做了奇怪的事情,打开相应的 CLAUDE.md 或 memory 文件,你就能清晰看到它被告诉了什么——那些指令和被记住的事实,正是它行动的根据。调试只需编辑一个文本文件。
值得问的是,OpenClaw 的系统为什么会变得这么复杂。一个可能的答案是,每一层都是为修补底下更简单一层的弱点而贴上去的。从文件里的纯文本开始,很快代理需要搜索这些文本的工具——于是搜索被另加上来。每增加一项功能,就多了一层可能出问题的地方。
基于 Claude Code 构建 Claudie
Every 的咨询团队需要一个 AI 员工来处理运营事务——跟踪客户合作、管理沟通、更新看板、跟进客户任务。知道了我们对两个工具的了解——尤其是 OpenClaw 的不可靠性——我们在 Claude Code 上构建了这个员工,Claudie。
我们的团队活在 Slack 里,所以 Claudie 也需要在那里。这就意味着要写一层把 Claude Code 连接到 Slack 的代码——大约 1,100 行 Python。它监听 Slack 里的消息,转交给 Claude Code,把响应流式传回,并处理格式化和文件上传等杂务。其他一切——会话、记忆、工具和技能——都交给 Claude Code 自己处理。
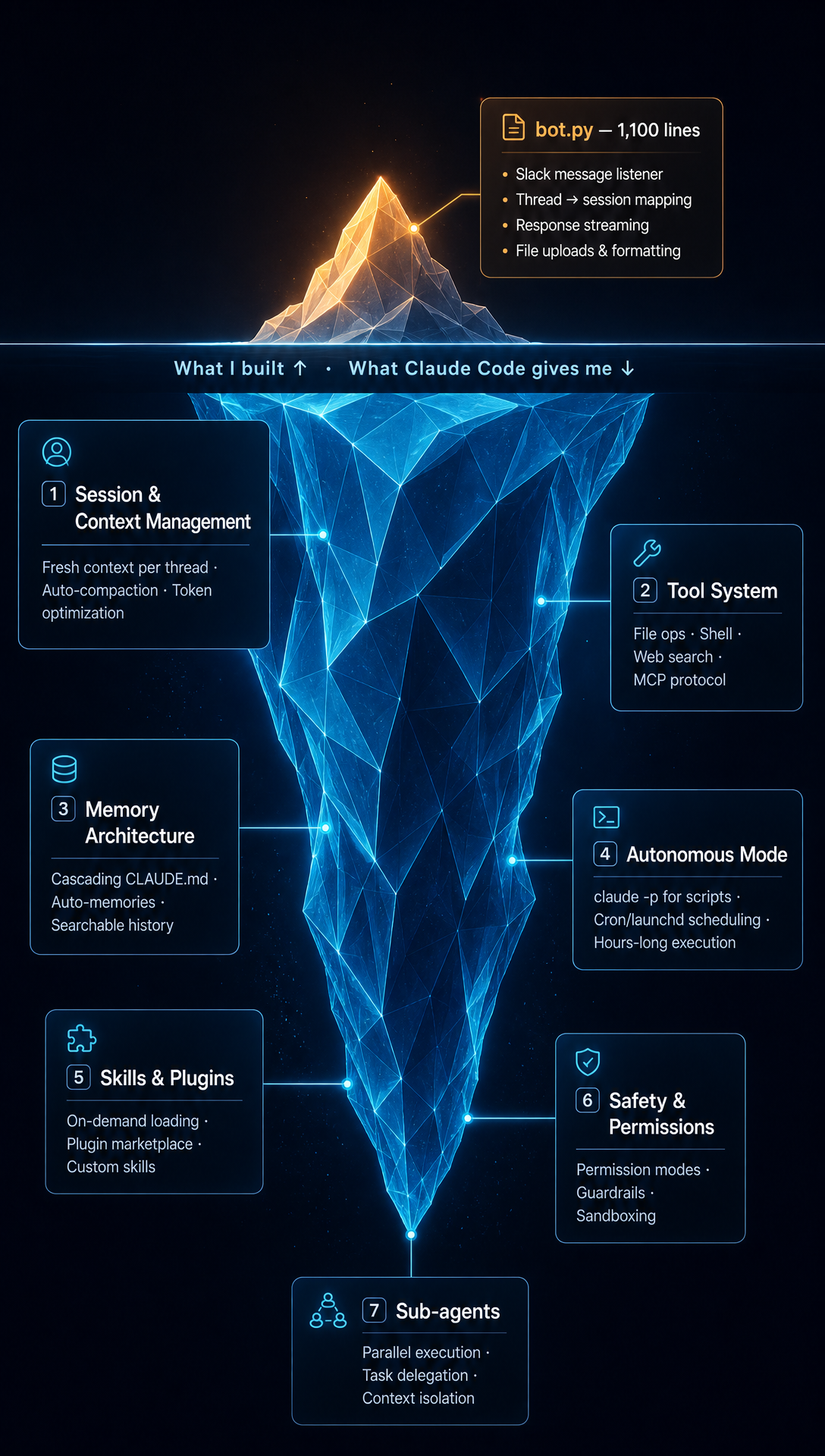 将 Claude Code 改造成 OpenClaw 式代理所需的投入示意图。Claude Code 是那个稳固的驾驭工具;上面我只写了一小层代码。
将 Claude Code 改造成 OpenClaw 式代理所需的投入示意图。Claude Code 是那个稳固的驾驭工具;上面我只写了一小层代码。
Claudie 24/7 运行在一台 Mac Mini 上,这样她不依赖任何人的笔记本电脑是否开机。她自己触发定时任务——团队的早报、pipeline 更新、收件箱整理、客户看板——并且接入了 Google Workspace、Asana、我们自己的 CRM、以及会议记录。三层记忆系统让她能跨成百上千次的内部(Slack)和外部(邮件、Granola)对话保持上下文。
日常维护她,大约 5% 是保持系统运行,30% 是管理记忆,65% 是构建新技能和决定自动化什么。记忆工作包括审计她记得什么、弄明白她为什么有时会在错误的时间召回错误的信息、添加新记忆、更新她的 SKILL.md 文件。
本质上,这说明:当一个工具的底层足够稳定,你才能真正把精力投入在"教 AI 理解业务"这件事上,而不是修修补补。
Claude Code 让我们学到关于 AI 员工的事
我几乎不花什么时间维护 Claudie 的驾驭工具层——那层把她连接到 Claude Code 的代码——因为不同于 OpenClaw,Claude Code 是一个稳定、工程扎实的基础。而这一点,正是 Claude Code 发布时大多数人没看到的。
OpenClaw 被当作 AI 员工来卖:"真正做事的 AI"。Claude Code 被当做编程工具来宣发。但在表象之下,Claude Code 已经拥有构建 AI 助手所需要的一切——工具、记忆和自主性。
任何人都能把技术跑起来。真正难的地方在于弄清楚该把什么交出去、以及怎么交。我们意识到 Claudie 在 Google Sheets 里的任务清单已经变得难以管理,于是我们把她迁移到 Asana 上。当现成的 Asana 连接器老是出故障,我们就自己构建了一个。我们得反复确认她应该从过往对话中记住多少——足以保持有用,但又不能多到让她失控。我们还必须教会她我们如何思考咨询这件事,而不只是教她使用软件。Claude Code 给了你一个足够稳定的基础,让你能把时间花在这种工作上——而不是花整个周末去弄清楚为什么 Claudie 突然没反应了。
OpenClaw 值得被赞扬,因为它让人们萌生了"想要一个 AI 员工"的念头。但构建这个员工的工具,其实早就静静地躺在开发者们的笔记本电脑上了。
核心启示:OpenClaw 与 Claude Code 在底层的"驾驭工具"性质上高度一致,但 Claude Code 以其更清晰的会话管理、可调试的纯文本记忆系统和更强的工程稳定性,实际上更适合作为构建可靠、可维护的 AI 助手的基石。问题的关键不在于功能的有无,而在于当系统出错时,你能多快地定位并修复问题。

Claude Code Is the OpenClaw Alternative You Already Have 的发芽报告
材料核心
OpenClaw 之所以爆红,是因为它让人们第一次看到“能动手做事的 AI”,但背后的技术本质只是一个模型驾驭层(harness)。Claude Code 从一开始就拥有完全相同的底层能力,只是因为被定位为“编码工具”而被公众忽视。作者通过构建实际 AI 员工的经验指出,Claude Code 在内存透明度、系统稳定性和可调试性上远优于 OpenClaw 的复杂架构,真正值得信赖的 AI 助手平台其实早已存在。
发芽 01:叙事框架如何遮蔽技术本质
种子
OpenClaw 与 Claude Code 的底层能力几乎完全重叠,但市场对两者的认知截然不同:一个是“革命性的 AI 员工”,另一个只是“好用的代码工具”。这背后的关键差异不在技术堆栈,而在产品被讲述的“故事”。叙事框架定义了用户看见什么、期待什么,甚至决定了一个工具能走多远——这种现象在科技史上反复上演。
1993 年,苹果公司推出了 Newton MessagePad,它被描绘成“个人数字助理”(PDA),一个可以识别手写、管理日程的未来设备。但当时另一家公司 General Magic 也在开发非常相似的手持系统,只是它们将它包装为“通信中介”——一种能在人与人、人与服务之间智能路由消息的代理。Newton 被记住为一次失败的手写识别实验,而 General Magic 的愿景虽然在商业上同样失败,却孕育了后来的智能手机操作系统和云服务概念。它们的硬件和软件内核其实惊人地相似:触摸屏、ARM 处理器、对象导向的嵌入式系统、红外通讯。差别在于,Newton 的叙事是“替代纸笔”,General Magic 的叙事是“数字代理人”。后者没有在当时落地,却种下了对智能代理长达三十年的想象,OpenClaw 正是这种想象在 2026 年的回响。
Claude Code 的问题在于,Anthropic 一直将它叙述为“编程工作流的一部分”。即便你可以用它管理整个电脑文件系统、调用外部 API、运行后台定时任务,大多数用户依然只把它局限在项目文件夹里,因为在他们的心智模型中,这只是一个终端里的编程伙伴。而 OpenClaw 的叙事一上来就是“存在于你生活中的 AI 员工”,这种框架激发了完全不同的尝试光谱:人们立刻开始让它打理收件箱、检查日历、管理 Notion。同一种底层技术,在“代码助手”的框架里被当成锤子,在“数字同事”的框架里被当成瑞士军刀。这不是市场不理性,恰恰是认知经济学:人类对工具的应用范围极度依赖最初的隐喻锚定。如果你把一把椅子叫做“梯凳”,人们会自动开始站在上面换灯泡。
Aha 瞬间
“技术本身的疆界,往往小于我们为它讲述的故事的疆界——而你永远只能坐进你所命名的那个箱子里。”
发芽 02:复杂性的自噬陷阱——为什么“更多”反而更不可靠
种子
OpenClaw 使用了八份引导文件、记忆固化“梦境”过程、多种搜索方式和一个百科式存储层来建造记忆系统,最终却因为层层补丁的复杂性而难以调试、容易悄然失效。Claude Code 的记忆只是一个可编辑的 Markdown 文件。这个对比映射出软件工程中一个古老的规律:每增加一层抽象来解决前一层的问题,系统理解的整体代价呈指数上升,而可靠性的天花板却在下降。
1975 年,计算机科学家弗雷德里克·布鲁克斯在《人月神话》里描述了“第二系统效应”:设计师在第一个系统成功后,倾向于把一切被压抑的想法都塞进第二个系统,让它变得臃肿、脆弱。OpenClaw 的记忆架构就是典型的第二系统:先用简单文本文件,发现搜索慢,于是加一个搜索层;搜索不够智能,再加一个索引层;索引层难以保持上下文,于是引入“梦境”过程来提炼;提炼出错,再补一个常识校验层。每次增加的复杂度都是为了修补前一个层次的正交缺陷,而整体组合谬误的数量随着层次乘积增长。当系统出错时,错误可能被任一层捕获、扭曲或传递,开发者站在迷宫入口,手握多个同样可疑的线索,却很难确定真正的源头。
与此形成对照的,是 Unix 哲学中的“做好一件事”:程序用纯文本流交换数据,每个组件简单到可被一眼看懂,组合之后却能实现复杂的涌现行为。Claude Code 的 CLAUDE.md 和记忆文件就是这种哲学在现代 AI 系统中的重演。你不需要追踪八个文件的交互规则,不需要逆向推断“梦境”流程的决策树,只要打开一个 Markdown,看到那一行“用户每周三上午 10 点有部门会议”被误记为周二,就能立刻修复。调试成本从侦探式推理降维为文本编辑,这不仅是时间节省,更是信任的维系——当 AI 行为异常时,你不是面对一个不可知的黑箱,而是能确切知道它被“灌输”了什么。
复杂性本身不是罪恶,但复杂性如果没有与之匹配的透明度,就会成为自噬的源头。OpenClaw 为追求无所不能的记忆,牺牲了可调试性;Claude Code 用似乎“原始”的简单机制,反而换取了持续运行的可信度。这让人想起托马斯·库恩对科学范式的观察:当一个领域的理论开始不断增设“特设性假设”来保护核心免于被证伪时,恰是范式走向危机的信号。OpenClaw 的层层补丁,正是技术架构中的特设性假设——它们维持了“记忆很聪明”的表象,代价是使系统无法被清晰理解和稳定演进。
Aha 瞬间
“你添加的每一个聪明层,都是未来需要解救自己的陷阱——真正的健壮,不是做得更多,而是让失败时能被一眼看见。”
你的思考空间
- 如果 Claude Code 一开始就被包装为“个人 AI 员工”而非“编程助手”,用户社区对它的使用方式和我们讨论它的语言会发生怎样的变化?产品命名的锚定效应在多大程度上可以被后期社区重新定义?
- 你的团队中是否也存在类似 OpenClaw 记忆系统那样的“特设性补丁”——为了快速解决问题而不断增加间接层,最终没有人能看清整个逻辑链条?如何为关键系统设立“可调试性”列为同等级别的一等需求?
- 当 AI 代理的记忆系统变得复杂到开发者自己也难以解释时,“信任”是建立在什么基础之上的?如果我们将对 AI 的信任类比于对人类的信任,那么“透明可审计的简单记录”是否应该成为代理伦理的一个基本标准?
- 文章提到 Claudie 的维护工作有 65% 是建立新技能和决定要自动化什么。那么,一个组织如何判断哪些工作适合交给看似“原始但稳定”的简单代理,哪些真正需要更复杂(可能也更脆弱的)AI 系统?这条界线的画法随时间会如何迁移?