我让 AI 审计我自己的职业生涯
原文:I Asked an AI to Audit My Own Career 作者:Katie Parrott 日期:2026-06-22
在我被 AI 带来的沉浸式工作状态弄得近乎恍惚时,我突然想起了我的 OKR。
我发表过随笔和指南,为我们的每日 newsletter 构建了智能体技能,产出了六份针对新 AI 模型的实操评测,还积攒了一大堆 Codex 项目,以至于我的桌面看起来有点令人不安。但我完全不知道,这一切是否累积成了我在六月底前承诺要完成的四个季度目标。
在焦虑感不断敲击着我的大脑时,我打开了Codex 中的职业教练项目,输入:“我们能检查一下我的 OKR 进度吗?进入职业教练模式。”
仅仅十分钟后,我就得到了一份全面而客观的意见。是的,我完成了我设定的 OKR。如释重负的感觉淹没了我。
AI 终于让我们能够真正做好管理学思想家**彼得·德鲁克(Peter Drucker)**所说的“反馈分析”(feedback analysis)——写下你对一项重大决策的期望,并在几个月后对比实际结果。而我以前构建的旧版本职业教练工具,只能知道我选择告诉它的信息。相较之下,Codex 可以主动搜索我桌面上的文件、Slack 聊天记录、Google Drive 以及网络上的记录。
这意味着,我可以拼凑出一幅关于我实际表现的准确图景——它不带恭维色彩,也不被灾难化思维扭曲——然后将之与我曾经宣称要做的事情进行比对。
我去寻找证明我已履行工作职责的证据,结果带回来的,却是一个比以往清晰得多的工作定位。
一个有“记忆”的教练
在解释 Codex 如何消解我对 OKR 的焦虑之前,先让我说明一下,我是如何设置能够客观追踪我绩效的职业教练的。
在我对 OKR 感到恐慌的几周前,我重新整理了桌面,用文件和文件夹构建了一个我和智能体都能理解的空间。
 我桌面上的职业教练文件夹,包含智能体首先读取的AGENTS.md文件,以及存放证据、计划、系统和引用资料的子文件夹,这些都是智能体在互动中可能用到的。(所有图片由Katie Parrott提供)
我桌面上的职业教练文件夹,包含智能体首先读取的AGENTS.md文件,以及存放证据、计划、系统和引用资料的子文件夹,这些都是智能体在互动中可能用到的。(所有图片由Katie Parrott提供)
Every 的同事们教会我,电脑上一个简单的文件夹,就可以容纳一套完整的智能体工作操作系统,围绕某项工作展开。其中的文件既能储存已完成的工作成果,也能告诉智能体去哪里找上下文信息、哪种类型的信息该信任哪些工具,以及如何处理它产出的成果。
对于职业教练来说,这个文件系统看起来大致如此:
career-coach-mode/
- AGENTS.md
- References/
- Plans/
- Updates/
- Evidence/
- Systems/
**References(参考资料)**存放了当前的目标和我的岗位说明。**Plans(计划)**则保存着目标进度的审计和弥合差距的行动方案。**Evidence(证据)**里是 OKR 仪表盘。**Systems(系统)**则登记了我正在积累的其他智能体和自动化程序。
 职业教练项目中的AGENTS.md文件,详细说明了在我提问之前智能体需要用到的背景信息。
职业教练项目中的AGENTS.md文件,详细说明了在我提问之前智能体需要用到的背景信息。
关键在于那个 AGENTS.md 文件,本质上是一份给智能体进入项目时加载的操作手册。我的这份文件告诉职业教练:哪些上下文信息是权威的,在给我建议之前必须读取哪些资料,如何区分证据与解读,以及不同类别的输出应该存放在哪里。所有这些背景信息,都来源于一次由 Codex 主导的访谈,然后它将访谈结果打包成了自己可读的文件。而我的工作,则是审阅并批准它的输出。
对此我做了三个决定。第一,我给职业教练在桌面上安了一个家,方便我随时访问。第二,我要求它在向我提出建议之前,必须读取文件夹里的所有必要背景材料。第三,我告诉它要把有用的输出保存到下次对话时可以找到的地方。Codex 则负责处理文书工作:它提议了具体的子文件夹和 AGENTS.md 文件里该放什么内容,并将每个产出物归类到正确的位置。这就是我与 Codex 之间的分工:我选择信息来源和边界,智能体则负责收集、比对并制定计划。
当我下一次打开这个项目时,我立刻感受到了差异。因为教练已经知道我上周更正了什么内容、昨天补充了什么证据,以及今天早上通过了哪份计划,我们完全可以从上次停下的地方继续。
Codex 对我进度的“判词”
Codex 打开了我用来记录与我的上司——Every 的主编 Kate Lee 共同设定的四个目标及十六项可衡量结果的文档。接着,它检查了我的项目文件夹,在 Slack 中搜索人们使用我构建的产物的迹象,核查了我已发表的作品和绩效数据,然后将这一记录与我原先的计划进行对照。
我原本预期它会确认我早已偏离了正轨,因为我默认的假设是:任何时候、总有哪里会出问题。但它向我展示,我离完成目标的距离,比我预想的要近得多。
我为 Working Overtime 专栏设定的发稿目标已经完成。一项 newsletter 实验已被整合进我们的共享编辑智能体 Andy,我的同事 Laura Entis 正在使用并优化它。Vibe Check 的测评流水线已产出了相当规模的试运行成果和草稿。
随后,大概是出于我的本性,我让 Codex “做个漂亮的小可视化图表”。它竟真的构建了一个交互式的 OKR 健康仪表盘,为每个目标配了一张卡片,展示评估背后的证据、仍缺失的内容,以及最有可能改善本季度表现的下一个动作。
 OKR健康仪表盘,展示目标进度、已确认凭证、证据缺口和下一步行动。
OKR健康仪表盘,展示目标进度、已确认凭证、证据缺口和下一步行动。
这张仪表盘纠正了我的自我评估,却拒绝让我沉浸于轻松感太久。“你的危险在于试图通过‘量’来证明影响力,”我的职业教练这样告诉我。它补充道,如果我希望我的工作能在组织内产生更大的效应,就需要主动把自己的工作分享给别人。
Codex 反馈中一次最扎实的验证,体现在我关于 Vibe Check 自动化的任务上。Every 的技术咨询主管 Mike Taylor 构建了一个用于端到端准备 Vibe Checks 的插件。我根据自己的一时想法到处微调,一直改到它在我的眼中毫无瑕疵为止。但事后,我并没有把它分享给同事,因为我怕我的修改反而让它变糟了。我害怕别人的评判,可真正能让这个系统变得更好的唯一路径,恰恰是倾听他们的想法。
正是在这里,我这个经过强化的职业教练触及了它的天花板:它能告诉我必须采取行动,却无法代替我迈出那一步。我最终还是把这个插件交棒给了编辑团队的 AI 助手 Andy。但我至今仍然做不到把它分享给一个活人,因为它还没到 尽善尽美 的程度。
OKR之外的真正影响力
有生以来第一次,我又开始对设定 OKR 充满期待了。
我的教练记录了我做了什么,在哪里产出了最强的结果,又在哪里回避了对采纳情况的衡量。我再也没办法为工作上的事过度自责了,因为我有了一个客观的评估器来让我对自己负责。
但教练还给了我另一件东西,让我理解了自己工作的影响力,并让我对公司的贡献感觉更积极。
我把一份关于 Every 品牌定位的内部文件分享给了它,并问它我在其中处于什么位置。它向我展示,我的工作是何以直接支撑起公司的战略的。
Working Overtime 为读者提供了描述“拥抱 AI 时的情感体验”的语言。我的指南则帮助他们付诸行动。Vibe Checks 在大模型发布的关键节点,展现了编辑团队的判断力。而我在建设方面的探索,越来越清晰地呈现出一个“从写作者向构建者”的转变轨迹。
它告诉我,我是为那些对 AI 感到好奇的人铺设的“入门口”。我会让一个读者产生这种想法:“好吧,如果她能行,也许我也能行。”
 Codex基于Every的品牌定位和对我的工作的洞察,为我构建的角色定位文档片头。
Codex基于Every的品牌定位和对我的工作的洞察,为我构建的角色定位文档片头。
这份角色定位分析,改变了我对待工作的方式。我在会议上更多地发言。我能更自信地说:“我想写这个话题,因为我觉得它会对这群人有所启发。”我也更坦然地接纳了自己作为“构建者”的身份。那些搭建起来的系统,不再感觉像是从我桌面上冒出来的某种奇怪业余爱好了。
我的起点,是去问 Codex 我在第二季度的目标上落后了多少。而记录反馈给我的,是宽慰,是“必须更响亮地谈论我所做的东西”的任务,以及一个关于我自身工作更宽广的图景。
现在我想问一个更好的问题:鉴于我已经向自己证明我有能力做的这些事,我该有足够大的雄心,去提议下一步去做些什么?
构建最小可用版本
你不必复刻我那个迷宫般的文件夹、经过四次迭代的实验品,也不必去造一个视觉冲击力堪比空管塔台的仪表盘,来搭建自己的 Codex 职业教练。你可以从一个问题开始:
相对于我这个季度所承担的目标,我站在什么位置?我下一步该做什么?
为了回答这个问题,创建一个项目文件夹。添加一份简短的说明文件,告诉智能体在向你提供建议之前需要读取哪些材料,哪些信息来源是权威的,如何标注不确定性,以及把有用的输出保存在哪里。
然后,给一个经你授权的智能体提供五类背景资料:
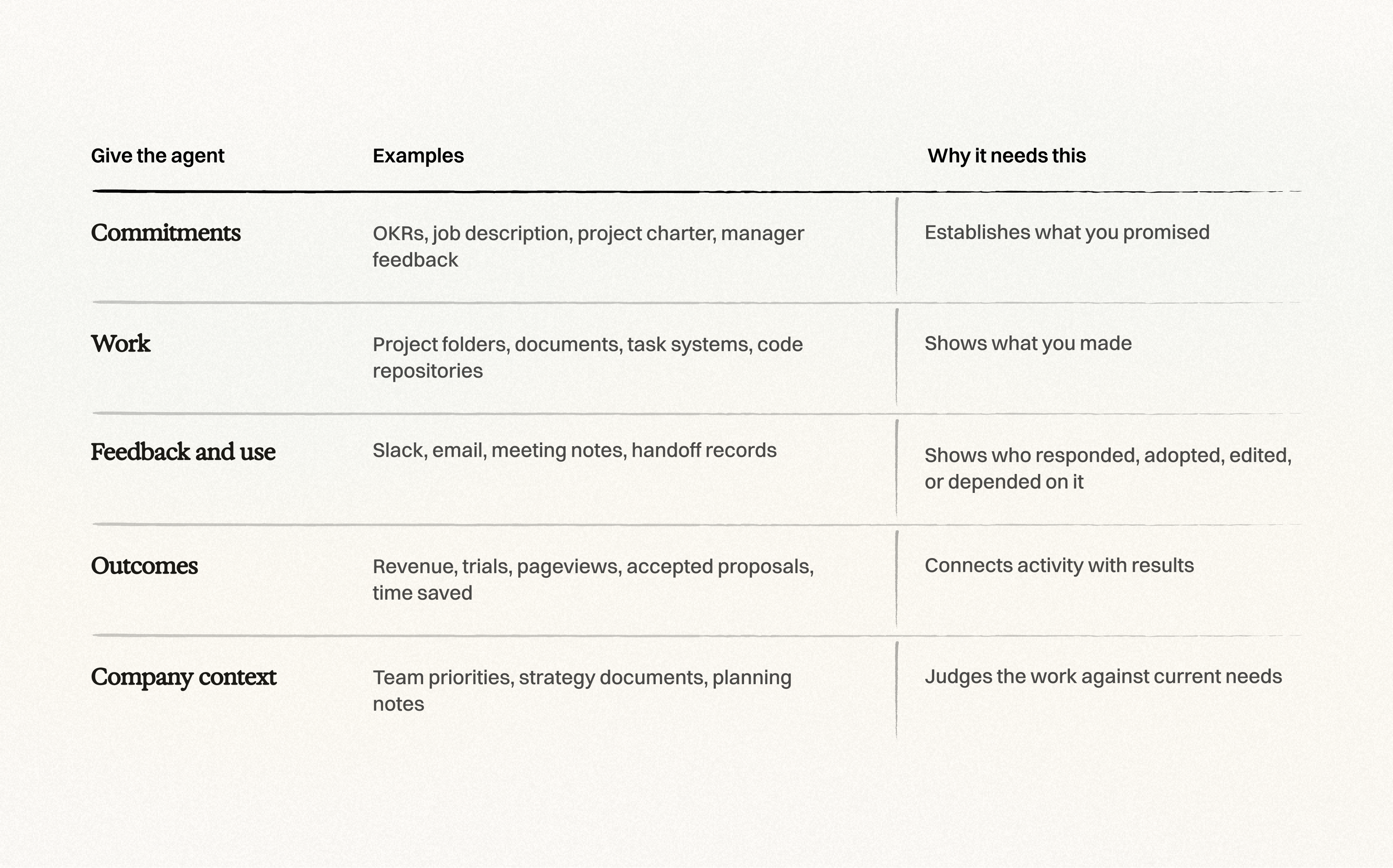
从你的目标、一个有代表性的工作文件夹、最近一次向领导汇报的记录,以及一份包含结果数据的文件开始。如果没有直接的 API 集成,你就手动导出或粘贴信息。但请务必遵守你所在公司的隐私、安全和访问规则。
给这个教练设定四条取证规则:
- 为每个重要结论,注明其信息来源。
- 区分“已确认的证据”、“解读”和“待定的问题”。
- 将意图、准备工作和讨论,视为比实际运行、交付、决策或结果更弱的证据。
- 在询问你的自我评估之前,先去查证记录。
紧接着,使用类似这样的提示词:
以注重证据的职业教练身份与我互动。根据我提供的资料中的工作记录、对话信息、反馈及产出数据,对比我当前的目标与职责。 针对每个目标,请展示:
- 已确认的进展,并附上信息来源链接或引用标记
- 有价值,但目前未被计入成果的工作
- 证据缺口,尤其是在采纳程度或影响力方面
- 目标已不再适配当前工作的地方
- 最有可能改进实际结果的单一下一步行动
然后,识别我在当前角色中发生的深层模式。务必区分“已确认的证据”、“你的解读”和“只有我能回答的问题”。最后,请制作一个可重复使用的仪表盘、证据列表、每周简报,或与上级对谈的议程表。当记录本身就能回答某个问题时,不要依赖我的自我评估作为依据。
把每次的输出结果保存到下次对话中可调用的位置。并将后续每一步的行动结果添加进来。在长期化的记录中更正来源上的错误。在每次与上级面谈前、每个周五,或一个计划周期结束时,重新运行一次这个审视流程。
无论你选择何种频率,记住要形成闭环:
承诺 -> 工作 -> 反馈或结果 -> 附来源的评估 -> 下一步行动 -> 新的证据
一开始,你只需要一张表:目标、已确认凭证、证据缺口,以及下一步动作。我的这张表,随着我发现了对这同一份记录的更多用法,后来陆续扩展成了仪表盘、采纳账本、领导层报告,以及角色定位文件。
这个系统,理应将最终的判断权,留给你自己。
核心启示:用 AI 构建职业教练,其真正威力不在于替你完成工作,而在于打破扭曲的自我认知,通过系统性地比对“曾经的承诺”与“客观的记录”,让你看清自己真实的贡献与真正该迈出的下一步。

《我让 AI 审计我的职业生涯》的发芽报告
材料核心
作者 Katie Parrott 利用 Codex 构建了一个基于证据的 AI 职业教练系统,通过客观追踪工作产出与既定目标的差距,不仅验证了自己的 OKR 进展,更重要的是发现了被自我怀疑掩盖的真实贡献——她不是“做得不够”,而是“说得不够”。
发芽 01:反馈的污点证人——为什么自我评估不可靠
种子
材料中的核心张力在于:作者默认“自己一定出了问题”,而 AI 教练用证据告诉她“你已经完成了目标”。这不是一个关于效率的故事,而是一个关于认知校准的故事。我们为什么需要外部证据系统?因为人类对自身表现的记忆不是录像机,而是一个带着强烈情感滤镜的不可靠叙述者。
2002 年诺贝尔经济学奖得主 Daniel Kahneman 在《思考,快与慢》中系统揭示了一个机制:可得性启发。我们判断某事发生的概率或自身表现时,依据的不是客观事实,而是最容易浮现在脑海中的例子。对于像 Parrott 这样高度自我要求的知识工作者,最易得的记忆是什么?是 Vibe Check 插件的“不完美”,是分享它时的恐惧,是那些散落在桌面上的半成品项目——这些焦虑信号远比“我按时完成了出版目标”这样平淡的事实更具记忆黏性。
这就解释了 Drucker 的“反馈分析”为什么在过去难以真正落地。Drucker 在 2005 年《哈佛商业评论》的《管理自己》一文中提出:写下你对每一项重大决策的预期,9-12 个月后对比实际结果。这个方法看似简单,但当他本人实践了 50 年后承认,执行起来极其痛苦。因为你要面对的不是“我做得够不够多”,而是“我的判断在哪里系统性失灵”。
Codex 在这里扮演的角色不是教练,而是反馈的污点证人。它不靠记忆,不照顾你的情绪,不放大近期的失败,不遗忘早期的成功。它检查 Slack 消息中同事是否使用了你的产出,核对项目文件夹中的证据链,对比你写下的目标与实际交付。当作者要求它“请做一个漂亮的小可视化”,那个 OKR 健康仪表盘不是装饰品——它是认知校准的物证。
Aha 瞬间
“你不能用焦虑的强度来测量目标的完成度。恐惧的声音总是比完成的声音更响亮,除非你给完成者一个麦克风。”
发芽 02:从作家到建设者的隐秘转换——AI 如何重构职业身份
种子
材料中最深刻但未被直接点名的线索是:Parrott 在用一个“建设者”的工具解决“作家”的自我怀疑。她用来追踪 OKR 的系统、构建 Vibe Check 插件的过程、为 Andy(编辑团队 AI 助手)设计技能——这些行为本身已经表明她的工作性质发生了质变,但她的自我认知还停留在“我是一个写作者,这些不过是桌面上的奇怪爱好”。
这是知识工作自动化的一个隐蔽效应:当你的产出不再是可见的文档,而是可被他人调用的系统、可复用的工作流、可交互的代理,传统的职业身份标签就会滞后于实际工作内容。
哈佛商学院教授 Amy Edmondson 的研究提供了一个有力的解释框架。她发现,当组织引入新技术时,最困难的不是技术学习本身,而是人们对于“我的工作到底是什么”的心理模型更新滞后。她称之为角色模糊性负担——员工会用旧脚本解读新行为,把自己的创造性系统建设归类为“不务正业”。
这就是为什么 AI 教练给出的角色定位如此具有冲击力。当 Codex 分析了 Every 公司的品牌定位文件,并将 Parrott 的工作嵌入其中后,给出的结论是:她是“AI 好奇者的上坡道”,是让读者产生“如果她可以,也许我也可以”想法的关键人物。这个定位之所以让她“在会议上更愿意发言”“更敢于说我想写这个”,不是因为获得了外部认可,而是因为她终于看清了自己已经在做的工作的真实性质。
值得注意的是,这种身份焦虑是正向的——它不是能力不足的信号,而是能力已经超出了旧框架的证据。正如心理学家 Lev Vygotsky 的最近发展区理论所揭示的:真正的学习发生在你能独立完成的和你需要帮助才能完成之间。Parrott 的“建设者项目”正是处在这个区间——她能独立完成,但没有足够的概念框架来承认它们是正式工作的一部分。
Aha 瞬间
“当你开始把职业转型误认为业余爱好时,你需要的不是更多的技能,而是一个能告诉你‘这早就是你的工作了’的镜子。”
发芽 03:古德哈特定律与 AI 教练的隐秘风险——当测量改变行为
种子
材料展示了 AI 教练的积极面,但其中隐含着一条暗线:当你知道自己被度量时,你会改变行为以适应度量体系。 作者提到她以前版本的职业教练工具“只知道我选择告诉它们的信息”,而 Codex“可以跨桌面、Slack、Google Drive 和网络去寻找收据”。这种从“自我报告”到“法务审计”的转变,既是解脱(你无法欺骗自己),也是新的压力源(你无法隐藏)。
这涉及到经济学家 Charles Goodhart 在 1975 年提出的古德哈特定律,其原始表述是:“一旦一个指标被用于控制目的,它就不再是一个好的指标。”这句话来自他对英国货币政策的观察,但完全适用于任何量化自我系统。
在职业审计的场景中,危险的形式更微妙。如果我知道 Codex 会在 Slack 里搜索“是否有同事使用了我的产出”作为影响力的证据,我的行为可能从“做对业务最有价值的事”,悄然滑向“做最容易在 Slack 上留下引用痕迹的事”。如果 OKR 健康仪表盘用绿色标记“已有收据”的项目、用红色标记“证据缺口”的项目,我会不会开始把大量精力花在“把模糊成果转化为可被机器识别的收据”上?
这并非否定 AI 审计的价值,而是指出一个必须被正视的张力。Parrott 本人已经触及到了这个边缘:当 AI 说“你的危险在于试图用数量证明影响力”,这实际上是在警告她不要落入指标主义的陷阱。AI 能够识别出她过度生产的行为模式,恰恰说明一个好的审计系统必须同时包含反审计的提醒。
材料中最重要的一条证据规则是:“在询问你的自我评估之前,先检查记录。”这句话本身就是对古德哈特定律的一种防御——它要求先建立客观基准线,再用主观判断去解释,而不是反过来。但真正的安全网可能在作者最后提出的那个问题上:“鉴于我已经证明自己能做到的工作,我应该足够雄心勃勃地提出什么?”这个问题引导的不是对过去指标的优化,而是对未来价值的重新定义——这正是走出度量陷阱的唯一途径。
Aha 瞬间
“一个好的 AI 教练不仅要告诉你完成了多少 OKR,还要警告你不要为了完成 OKR 而改变工作的本质。最有价值的输出,是那个让你不再需要盯着仪表盘的问题。”
你的思考空间
如果你像 Parrott 一样搭建一个基于证据的 AI 职业审计系统,你最大的恐惧是什么:是发现你做得不够,还是发现你一直在错误的方向上“做得很好”?
在“承诺 → 工作 → 反馈 → 评估 → 下一步行动 → 新证据”的闭环中,哪个环节是你当前最缺少证据的?如果 AI 能填补这个空白,你愿意让它访问哪些数据源?
古德哈特定律在你目前的绩效考核体系中如何运作?有没有哪个指标在你开始关注它之后,就不再反映真实价值了?
Parrott 的角色转变(从作家到建设者)是被 AI 教练“发现”的,而不是她主动宣布的。在你的职业生涯中,有没有哪些已经发生的转变,因为你没有给它们命名,而一直被你视为“副业”或“偶然”?
德鲁克的反馈分析法要求你写下预期后等待 9-12 个月再对比。如果 AI 能将这个周期缩短到每周一次,你是否有勇气接受如此高频率的认知校准?适度的“无知”对持续行动是否也是一种保护?