探秘百智能体软件工厂:并行 AI 编程的现状与未来

迷你风向检查:Gas City
一窥尚未准备好投入实用的未来
今年早些时候,知名软件工程师 Steve Yegge 发表了一篇广为流传的文章,介绍了 Gas Town——一个能让开发者同时协调 20 到 30 个 AI 编程智能体在同一代码库上工作的开源工具。上周,Every 的技术咨询主管 Mike Taylor 得以一窥多智能体工程的未来,这次的主角是 Gas Town 的继任项目 Gas City。该项目在 Yegge 的祝福下,由长期从事开发者工具的老将 Chris Sells(曾将 Google 的开源应用构建工具包 Flutter 发展到 300 万开发者)和前 Block 技术主管 Julian Knutsen 重构为一个工具包。Mike 在纽约的一次研讨会上,与其他二十多位工程师和首席技术官一起试用该项目,Sells 和 Knutsen 远程接入进行指导。
简而言之: Gas City 有一些反映软件开发方向的前沿理念,但目前还不适合大规模使用。
Gas City 是什么: 对开发者而言,并行运行多个编码智能体已经是基本操作。但要让它们完成任何有用的工作,就需要一个协调系统来相互分配任务、审查彼此产出,并且不干扰各自的分支——然而,还没有人能完美解决这个问题。像 Gas City 这样的“软件工厂”是一种解决方案:一个将任务分派给小型智能体团队、调度它们的工作并判定任务完成的编排系统。
Sells 和 Knutsen 用 Gas City 来构建 Gas City 本身:Knutsen 位于亚特兰大的服务器运行着大约 100 个智能体,每天合并约 50 个拉取请求——这相当于一个小团队的工作产出——每天消耗大约 10 亿个 token,大致相当于维基百科英文语料库的五分之一。
哪些地方行得通: Gas City 建立在软件工程领域的三个理念之上,即便你从不碰这个工具包,这些理念也值得内化。
- 暗工厂与亮工厂: 你的工作中,需要人和智能体相互沟通的部分(计划、设计、审查)可以保持在可视状态,被视为“亮”的部分;而智能体独立完成明确定义的工作部分,则在后台“暗”中进行。随着你对智能体产出的信任增加,你可以将流程中更多的部分移入暗工厂。
- 一宠多畜: 多智能体工程的未来,可能会围绕着一个你直接对话的、持久且有名字的“主管”来组织。在 Gas City 中,这名主管被称为“市长”,它负责将任务分派给匿名的、一次性的“工人”,这些工人被称为“臭鼬”,它们完成一项工作后就会关闭。这样它们可以在执行任务时,既不会在上下文中迷失,也不会互相妨碍。换句话说,你无需管理一百个独立的智能体,只需要管理一个对话,而协调工作全由“市长”完成。
- 每次代码审查都有多重意见: 将相同的代码同时交给 Claude、Codex 和 Kimi 审查,从多个角度发现问题。用三种不同的模型会发现不同的 bug,这不同于将同一个模型运行三次。
哪些地方可以更好: 在 Gas City 中,每个任务都会启动一个全新的智能体会话,它不记得先前的步骤。这导致智能体浪费计算周期去重新读取其他智能体所产生的上下文,并会错过单一连续会话才能捕捉到的关联。成本也是一个挑战:一个六步工作的成本可能是一个 Claude 会话的六倍,费用会迅速攀升。该工具包仍处于实验阶段——即便有导师支持,满屋子经验丰富的工程师也花了整整一天才让它跑起来。
驱动该系统的任务追踪器 Beads 是为智能体优先构建的。它在命令行中运行,而不是作为可视仪表板,这对智能体来说没问题,但对希望一目了然看到所有信息的人类而言则困难得多。因此,在生产环境中使用 Gas City 的团队通常会将其与 Jira 或 Linear 配对使用,导致任务被放在两个地方,而非一个。
此外,Gas City 构建时基于一个假设:AI 模型需要手把手引导才能保持在正轨上。但如今模型已经足够强大,以至于 Gas City 中的一些纠偏设计,比如捕捉错误的审查循环和防止智能体跑偏的中间任务检查点,现在已经很大程度上不再需要了。最后,Gas City 使用了一些刻意不常见的词来指代不同的输入、参与者和工作流——比如用 “beads” 指代任务,用 “polecats” 指代工人,用 “refineries” 指代处理步骤——这对刚接触这项技术的团队来说可能会造成困扰。
结论: 🟨 技术咨询主管 Mike Taylor 表示:“学习它的理念,但目前先跳过这个工具包。”
如果你已经在并行运行 10 个以上的 Claude Code 会话并阅读源码,那么 Gas City 值得一看,因为它是如何处理这种级别编排的一种有见地的方案。对于其他人来说,接受其理念,然后保持观望。几周前发布的 OpenAI 的 Symphony 是一个类似但更易用、更面向企业的版本:一套书面规则,可将你现有的 Linear 面板变成智能体工作的仪表板。这更贴近现今软件工程师的工作方式,并且不需要像 Gas City 那样改变行为习惯。
借鉴这个工作流
在发布前,用 Grok 检测你的 X 帖子
xAI 上周 开源了其推荐算法,展示了 X 平台在决定哪些帖子会出现在用户的“为你推荐”信息流中时所考虑的因素。这其中包括一个由 Grok 驱动的“爆款分类器”,它通过对每篇帖子进行质量和垃圾信息评分,来决定是否应获得更多分发。那么,为什么不自己先跑一遍同样的检测呢?
- 将你的草稿连同 X 的评分提示词一起粘贴给 Grok。 要求 Grok 返回四项内容:
quality_score(质量分)、slop_score(垃圾信息分)、isHighQuality(一个布尔值,判定帖子是否达到质量标准) 和话题标签。该分类器会读取文本、图片和视频。使用这条提示词:“像 xai-org/x-algorithm 的爆款分类器那样,为这篇 X 帖子打分:返回 quality_score (0–1)、slop_score (1–3)、isHighQuality 布尔值和话题标签。” - 重写任何质量分低于 0.4 或垃圾信息分高于 1 的帖子。 用户快速划走或举报的帖子会受到惩罚,而能引发回复和驻留时间的帖子则获得奖励。要提升分数,就用一个能让人停下手指的第一句开篇,举出一个具体的经历、事件或数字,并删掉所有读者可能会略读的内容。本质上,这揭示了一个逻辑:只要用户划走,算法就会将帖子标记为“未驻留”,并降低其推荐权重。
- 将每日发帖数限制在两到三条。 算法会在排名系统中大幅压低你的第四条帖子的权重,到第八条时权重会趋近于零。与其发布多篇让人过目即忘的帖子,不如将精力投入到更少、更能吸引人停下来并产生互动的帖子上。
信号
HTML 正在成为新的 Markdown
发生了什么: 直到几周前,Markdown 这种轻量级文本格式化系统,还是 AI 智能体文档的终极之选。因为智能体已经受过海量 Markdown 训练,可以流利地读写它。然后,在 5 月 8 日,Anthropic 的 Thariq Shihipar 发表了一篇 X 帖子,标题为 “HTML 的不合理有效性”,提出智能体在创建文件时应该选择生成单文件 HTML。该帖子在 16 小时内获得了 440 万次浏览。三天后,Andrej Karpathy 对此表示支持。长期研究 Markdown 的倡导者 Simon Willison 也 改变了看法,认为既然现在上下文窗口已经足够大,就没有理由再忍受 Markdown 的格式限制了。
为何重要: HTML 能做到 Markdown 做不到的事,从样式化的表格和可折叠区域,到内嵌图表和轻量级的 JavaScript。我们之前觉得 Markdown 是正确答案,前提是人类仍会编辑智能体生成的内容,因为它对人类和智能体都具有可读性。然而,一个正在发生的转变是,智能体越来越不需要人类干预就能生成文档。
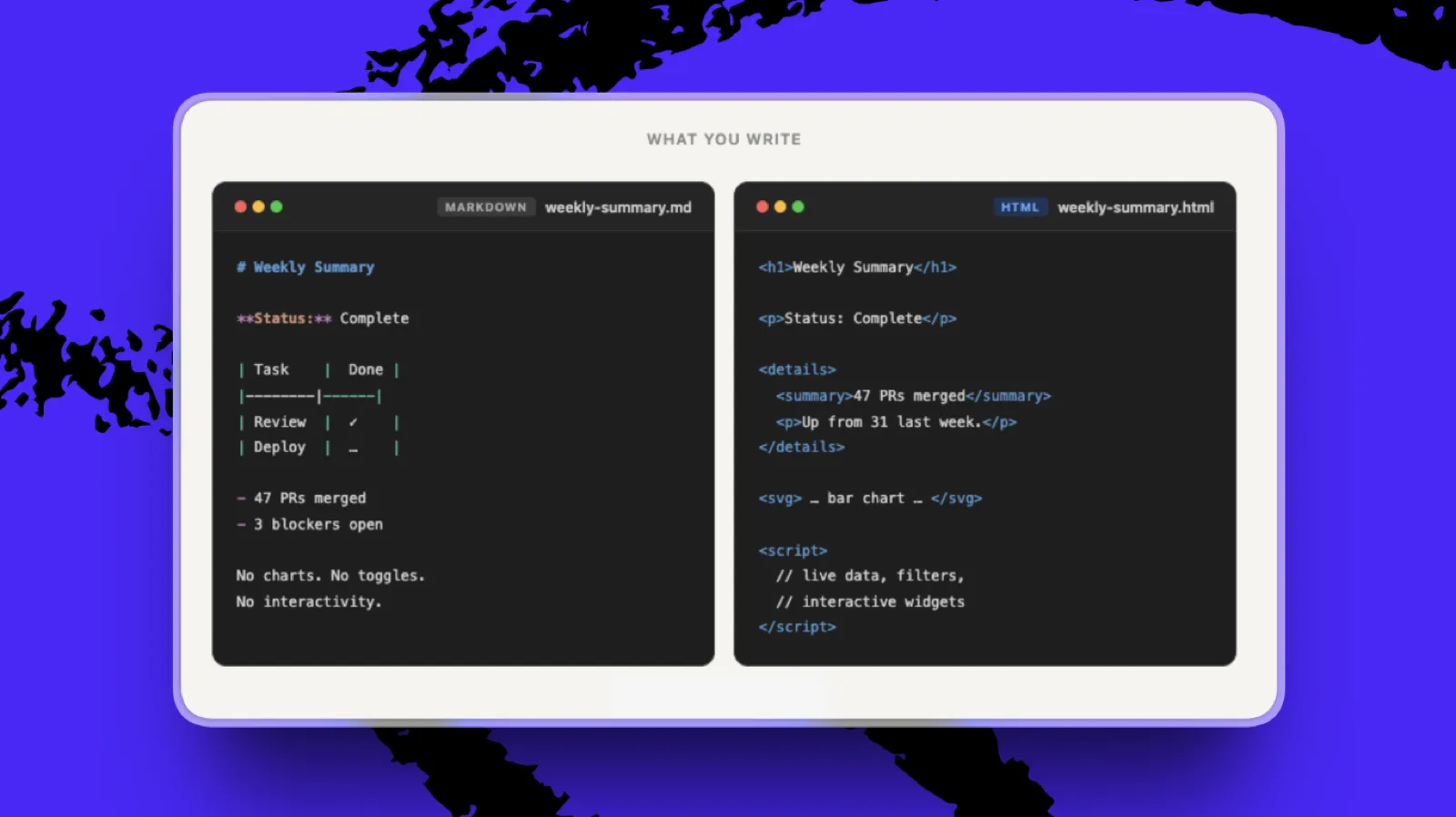 左侧的 Raw Markdown 比右侧的 HTML 更具可读性和可编辑性。(所有图片均由 Katie Parrott 提供)
左侧的 Raw Markdown 比右侧的 HTML 更具可读性和可编辑性。(所有图片均由 Katie Parrott 提供)
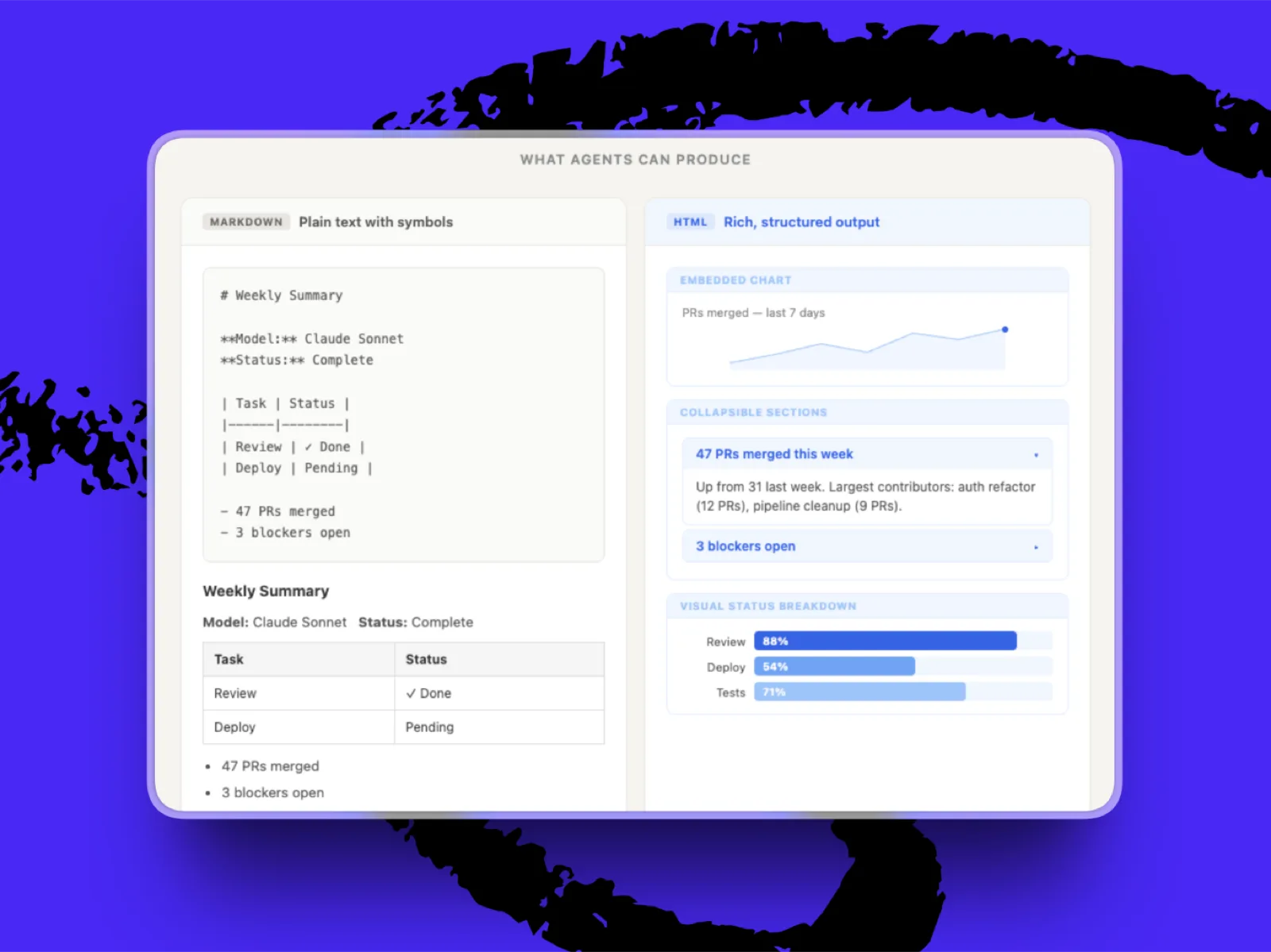 左侧的 Markdown 是纯文本格式,而右侧的 HTML 则允许输出更丰富的内容,如仪表板、图表和交互式区域。
左侧的 Markdown 是纯文本格式,而右侧的 HTML 则允许输出更丰富的内容,如仪表板、图表和交互式区域。
不过,这里有一个难点:我们用来分享和讨论文档的工具,比如 Slack 和 Google Docs,都是为 Markdown 和纯文本构建的。Slack 会在消息中预览 Markdown 文件,而 HTML 文件则显示为一个你必须下载的附件。Google Docs 的批注功能和 GitHub 的差异对比也不知道该如何处理一个自包含的 HTML 文档。问题在于,当智能体开始默认生成 HTML 时,我们的工具将需要同步进化才能跟上。
本周行动指南:
当你在 Markdown 和 HTML 之间做选择时,问自己一个问题:这篇文档是用来编辑,还是仅供消费?
- 如果它将被编辑或作为源文件解析,选 Markdown。 这包括草稿、计划、简报、系统提示词和 AGENTS.md——任何人类会继续完善,或者智能体将作为指令读取的文件。
- 如果它是供人类阅读的最终成品,选 HTML。 这类资产包括研究摘要、每周回顾、仪表板或规格演示。
更正:本通讯的早期版本不准确地描述了 Markdown 和 HTML 之间的区别。关键区别在于文档目的是用于编辑还是供消费。我们已对语言做了更新以反映这一点。
Every 内部实践
在公开频道与我们的 AI 智能体协作
与智能体高效协作是一项很新的技能,以至于目前还没有真正的“最佳实践”。因此,Every 的团队开始互相学习。
上周,Every 的首席运营官 Brandon Gell 和市场营销主管 Douglas Brundage 各自在 Slack 上建立了公开频道,展示他们与智能体的协作过程,团队中的任何人都可以旁观。48 小时内,公司上下有十几人加入并默默观察。
其核心理念是,每一个通常会在私信中进行的请求都会被放到这个公开频道里。Brandon 让智能体从 Stripe 中提取订阅用户的地理位置分布。Douglas 则要求他的智能体对照经典的市场营销框架来评估客户调查问卷的回复。还有一个关于是否要将智能体接入 Flora API 的讨论,产生了长达 41 条消息的线程。
这些纠偏过程在频道里就成了有用的学习材料——观看 Douglas 告诉智能体,其调查分析只是在“执行研究”而非“挖掘结果以获得战略清晰度”,让旁观者理解了智能体的局限性和隐藏的假设,这将帮助他们在自己的智能体工作中留意类似问题。智能体也能从互动中学习:Brandon 已经将所有任务都通过他的智能体路由一整周了,即使是那些他自己做会更快的事也不例外,这样智能体就能观察他的工作方式,并在最后编写出自己的技能。目前看来,学习如何与智能体协作的最佳方式,可能就是观察别人是怎么做的。
核心启示:当前多智能体软件工程正在从“能跑起来”迈向“能协调起来”的阶段,其核心瓶颈已不在于模型能力,而在于设计人类意图、智能体间上下文管理与现有工具链之间的适配系统。
Gas City 与 AI 软件开发工厂 的发芽报告
材料核心
Katie Parrott 的这篇通讯报道了三个正在重塑 AI 辅助开发的关键信号:Gas City 这种“百代理并行”的软件工厂实验揭示了多代理编排的核心原则但尚未成熟;HTML 正取代 Markdown 成为代理产出的首选格式,因为当人类不再编辑原始输出时,格式的丰富性比可读性更重要;以及 Every 团队如何通过公开代理工作流来加速组织学习。
发芽 01:暗工厂——知识的去人化生产线
种子
Gas City 提出的“暗工厂 vs 明工厂”隐喻,不只是划分自动化程度的工具,而是在重新定义知识工作中“人必须看见什么”。这个二分法揭示了一个深层转变:软件工程正在从以人为中心的协作工艺,走向以机器吞吐量为优先的生产系统。
故事主体:福特流水线的启示与美国军事后勤
1913 年,亨利·福特在高地公园工厂投下第一代移动装配线时,并没有让工人的工作消失——他让工作变得隐形。传统汽车制造中,熟练技工需要看见整个底盘才能安装零件;装配线上,工人只需要看见眼前 3 英尺内的操作面。福特的洞见是:把认知范围压缩到任务粒度,才能实现速度。到 1914 年,福特的单台 T 型车装配时间从 12.5 小时压缩到 93 分钟。
Gas City 的“暗工厂”逻辑延续了同一模式,但对象从体力劳动变成了知识劳动。Yegge 和 Sells 的设计选择——每个“臭鼬”代理只执行一个任务后关闭,不读取前置代理的上下文——本质上是在用认知减少换取并行能力。这在技术上看起来像浪费(代理重复读上下文,成本翻倍),但在福特逻辑下是理性的:只要单任务的错误率够低,多付的推理成本低于协调成本时,这种浪费就是可接受的。
但这引出一个紧张点。福特工厂把工人变成了机器的延伸,但工人是自愿的(或至少可以用工资补偿);而软件代理没有讨价还价权。真正的张力在于:当我们把设计、审查这些“明工厂”环节也逐步推入黑暗时(正如 Gas City 建议的“随着信任增加,把更多流程移入暗工厂”),人类工程师会从代码的决策者退化成方向的指定者,再进一步退化成方向的批准者。每一步都意味着知识的去人化——代码中嵌入了没有人完整理解的决策链。
2003 年,美国军事后勤系统引入了一个叫 JFAST(联合流与运输分析系统)的 AI 规划工具,用于自动生成波斯湾兵力部署方案。2003 年伊拉克战争初期,JFAST 生成的方案被多次无修改批准执行,直到有一次其输出的港口调度计划在前线造成了 72 小时物资积压。回溯调查发现,没有人能解释代理当时的决策路径,因为没有一个人类规划者阅读了方案的全部假设。这正是暗工厂的隐性代价:当代码的生产链对人类透明但不必读时,理解和责任是分离的。
Aha 瞬间
“暗工厂不是关于代理是否值得信任——而是关于人类是否还保存着理解错误的能力。福特的工人至少知道自己的工位为什么这么设计;未来的软件工程师可能连这个都放弃了。”
发芽 02:格式之争——当读者不再是人类
种子
从 Markdown 到 HTML 的转变,表面上是关于排版功能,实际上揭示了 AI 工具链中一个隐秘的分水岭:文档从“沟通媒介”变成了“纯消费产品”。当人类不再编辑代理产出的内容时,可读性的定义从一个格式问题变成了一个受众问题。
故事主体:Xerox PARC 的 WYSIWYG 革命与 LaTeX 的幸存
1981 年,Xerox PARC 发布了 Star 工作站,首次实现了“所见即所得”(WYSIWYG)文档编辑。当时的主流观点是:所有文档最终都会变成用可视化编辑器直接排版,纯文本标记语言(如 runoff 和 troff)会消亡。但 LaTeX,Leslie Lamport 在 1984 年基于 Donald Knuth 的 TeX 构建的标记语言,不仅没消亡,反而成为数学和计算机科学界的标准——原因恰恰在于它的“人类可编辑性”。LaTeX 的纯文本源码可以被 diff、被 grep、被脚本批量处理、被版本控制系统追踪。这些特性不是给读者的,是给写作者和协作者的。
现在,这个历史弧线被逆转了。Thariq Shihipar 那篇“HTML 的不合理有效性”在 16 小时内获得 440 万浏览,不是因为它发现了 HTML 的新功能——HTML 一直有这个能力——而是因为它命名了一个范式转移:当代理取代人类成为第一作者时,那些为人类作者优化的特性(可 grep、可 diff、可纯文本阅读)突然变成了过度约束。HTML 在源文件层面的“丑陋”不再是问题,因为没有人需要看源文件。就像 PDF 在 1990 年代取代 PostScript 成为文档交换格式一样——不是因为 PDF 好编辑,而是因为它根本不需要被编辑。
但这个转变有一个隐藏的成本。文章提到 Slack 预览 Markdown 但把 HTML 当作附件下载,Google Docs 和 GitHub diff 无法处理 HTML。这不只是工具兼容性问题——这是版本控制和集体协作的退场。当代理产出 HTML 时,人类失去了轻量级修改的能力(修改 HTML 源码比修改 Markdown 心智负担高得多),这意味着人类被强制推向了“要么全盘接受,要么否掉重做”的二元选择。这恰好又回到了第一部分的暗工厂问题:如果连输出格式都禁止人类插手,那么人类的监督就降格为只看渲染结果的消费者审阅,而不是对文档逻辑的参与。
Simon Willison 在 2026 年 5 月的博客中说到“上下文窗口足够大,没有理由再接受 Markdown 的限制”——这句话的逻辑预设了代理是唯一作者。但 Every 团队的实践(公开 Slack 频道中的代理工作流)恰好证明了一个反趋势:当团队需要共同学习如何使用代理时,交互过程本身必须是可编辑的、可见的、可讨论的。HTML 的消费品美学关闭了这个学习通道。
Aha 瞬间
“从 Markdown 到 HTML 的迁移,真正的代价不是排版能力,而是否决了人类轻量干预的通道。当一切输出都是不可编辑的渲染结果时,人类的角色从编辑变成了评审委员会,只负责按通过按钮。”
发芽 03:公开学习——把代理变成透明的学徒
种子
Every 团队把代理工作流公开到 Slack 频道,表面上是为了知识共享,实际上在有意制造一种不对称的透明:人类的工作对其他人透明,代理的局限性对人类透明。这种做法重塑了“最佳实践”的形成机制——不是靠抽象总结,而是靠围观具体的失败。
故事主体:丰田的墙与航空业的开放学习系统
1936 年,丰田自动织机公司的创始人丰田佐吉在工厂里推动了一项令当时的日本制造业感到困惑的做法:任何工人发现生产线问题时,不仅要停下来,还要把问题的描述写在车间中央的一块大木板上,用粉笔圈出来。后来的丰田生产系统把这块板制度化为“大房间”(Obeya),所有主要决策、问题、错误都贴在墙上供任何人观看。丰田的逻辑是:问题隐藏的成本远大于问题暴露的尴尬。一个工人拧错了螺丝,如果只有他自己知道,下一个班次的工人会重复同样的错误;但如果写在墙上,产线上的所有人都会绕过这个坑。
Every COO Brandon Gell 和营销负责人 Douglas Brundage 的做法,本质上是在知识工作中重建了 Obeya。他们把代理的工作过程——包括错误的输出、需要纠正的指令、41 条消息的 API 讨论——全部暴露给公司里任何想观望的同事。文章特别提到一个细节:“Douglas 告诉代理它的调查分析是‘进行调研’,而不是‘从结果中挖掘战略清晰度’”——这种纠正对于当事人来说是个小调整,但对于旁观的同事来说,这句话瞬间揭示出代理的深层假设:它理解分析等于汇总,但不理解分析等于提炼论点。这种知识不是通过文档传承的,是通过目睹具体失败传承的。
这与航空业的并行学习系统形成呼应。1970 年代,美国联邦航空管理局(FAA)强制推行 ASRS(航空安全报告系统),要求飞行员和空管匿名报告任何操作偏差,且这些报告对全行业开放阅读。到 1990 年,ASRS 数据库中积累的 40 万份报告成为了航空安全培训的核心教材,但关键的是,每一份报告都不是抽象的安全准则,而是一个具体的个案:某年某月某航线,某个飞行员在怎样的条件下,犯了一个他以为只有自己会犯的错误。这正是 Brandon Gell 想让代理“记录他一周的工作以便代理写自己的技能”的意义——不是让代理一次做对,而是让代理通过积攒案例来学习,同时让围观的人类也从案例中学习。
但 Every 的做法也隐含一个问题:他们会把代理的错误保持公开多久?丰田的墙是永远开放的;航空安全报告是永久归档的。但企业 Slack 频道中的代理交互,通常不会成为永久的培训材料。如果这些交互在一段时间后被归档或遗忘,组织学习就变成了短时记忆。长期来看,一个真正有效的代理学习系统需要的不是 Slack 频道的公开,而是一个可查询的“代理错误模式库”——就像 ASRS 那样的归档系统。
Aha 瞬间
“公开代理工作流的价值不在于分享胜利,而在于暴露错误。丰田花了半个世纪才让日本制造业接受‘把错误写在墙上’的文化;AI 代理正在逼硅谷在几个月内学会同样的习惯。”
你的思考空间
如果你所在的团队开始推行“暗工厂”模式,将更多决策交给代理链而不是人类审查,你如何设定一个“不可暗化”的最低监督边界?这个边界应该放在哪里——代码提交?架构决策?还是需求定义?
当代理默认输出 HTML 而不再是 Markdown 时,这意味着版本控制系统(如 Git)对文档变更的追踪能力会下降。这是否会催生一种新的“只读文档文化”,其中文档要么是活的渲染品,要么是被废弃的过去版本?这种文化对政策文档、法律协议等需要历史追溯的场景会产生什么影响?
Every 的公共频道实验让同事们从旁观错误中学习。但代理的错误模式是否会随着模型升级而改变?如果 Claude 4.5 犯的错误和 Claude 4 完全不同,那么从今天的交互中学到的经验会在三个月后失效——我们如何在一个持续变化的代理能力曲线上建立稳定的组织知识?