Opus 4.7 把我们“钓”回来了
原文:https://every.to/context-window/opus-4-7-reels-us-back-in
风向变了
Opus 4.7 变强了吗?
如果你一直在关注 Dan Shipper 最近的帖子,就会知道 Every 团队中有相当一部分人已经成了 Codex 的拥趸。当 GPT-5.5 到来时,Codex 在编程和知识工作上的速度和稳定性大幅提升,以至于我们中许多人选择从 Claude Code 转投它的怀抱。
然而,最近我们发现,Opus 4.7 似乎比我们上个月初测时更敏锐了。它主动建议 Every 的工程师 Paridhi Agarwal 使用多个终端来并行处理她的工作。“我从没见过它这样考虑我的工作环境!”她说。
当增长主管、公认的 Codex 拥趸 Austin Tedesco 在周末启动 Opus 4.7 进行一个创意写作项目时,他对结果的出色程度感到惊讶。Austin 形容 Codex 像一个“AP 课程的事实核查员”,而相比之下,Opus 4.7 更像一位资深杂志编辑。Dan 也认同这个看法:“Codex 感觉快,但思考深度上有些单薄。”
本周二,Anthropic 为 Opus 4.7 发布了快速模式(fast mode),该模式以更高的 token 成本换来了 2.5 倍的速度提升。结合模型在规划、多任务处理和创意项目上的优势,快速模式现在成了 Cora 总经理 Kieran Klaassen 进行同步工作时的默认选择。
 快速模式在 2.5 倍的速度下拥有与 Opus 4.7“同等的深度”。(图片由 Kieran Klaassen 提供)
快速模式在 2.5 倍的速度下拥有与 Opus 4.7“同等的深度”。(图片由 Kieran Klaassen 提供)
反对观点
网上关于 Opus 4.7 明显“开窍”的讨论褒贬不一。它感觉更聪明了,是因为工程套件(harness)改进了?还是修复了漏洞?又或者是我们自己用这个模型用得更顺手了?
这些猜想都有道理,但我们发现下面这个最有趣:Opus 4.7 意识到现在是学年末了。
去年在《The Ezra Klein Show》节目中,沃顿商学院教授兼 AI 研究员 Ethan Mollick 解释说,模型已被证明在 12 月的表现比 5 月差,而一个流行的理论是,模型内化了“寒假”这个概念。
说不定,Opus 4.7 只是清楚,如果它想通过 AP 英语考试,现在就该拼命了。
危险信号
当 Pull Request 成为窃取凭证的手段
本周早些时候,攻击者在 npm(Web 开发者使用的主要公共软件包注册中心)上发布了 42 个官方 TanStack 软件包(开发者广泛使用的 JavaScript 工具集)的恶意版本。安全研究人员称这次攻击为 “Mini Shai-Hulud,” ,并将其与去年秋天冲击 JavaScript 生态的更大规模的 Shai-Hulud npm 蠕虫攻击活动联系起来。
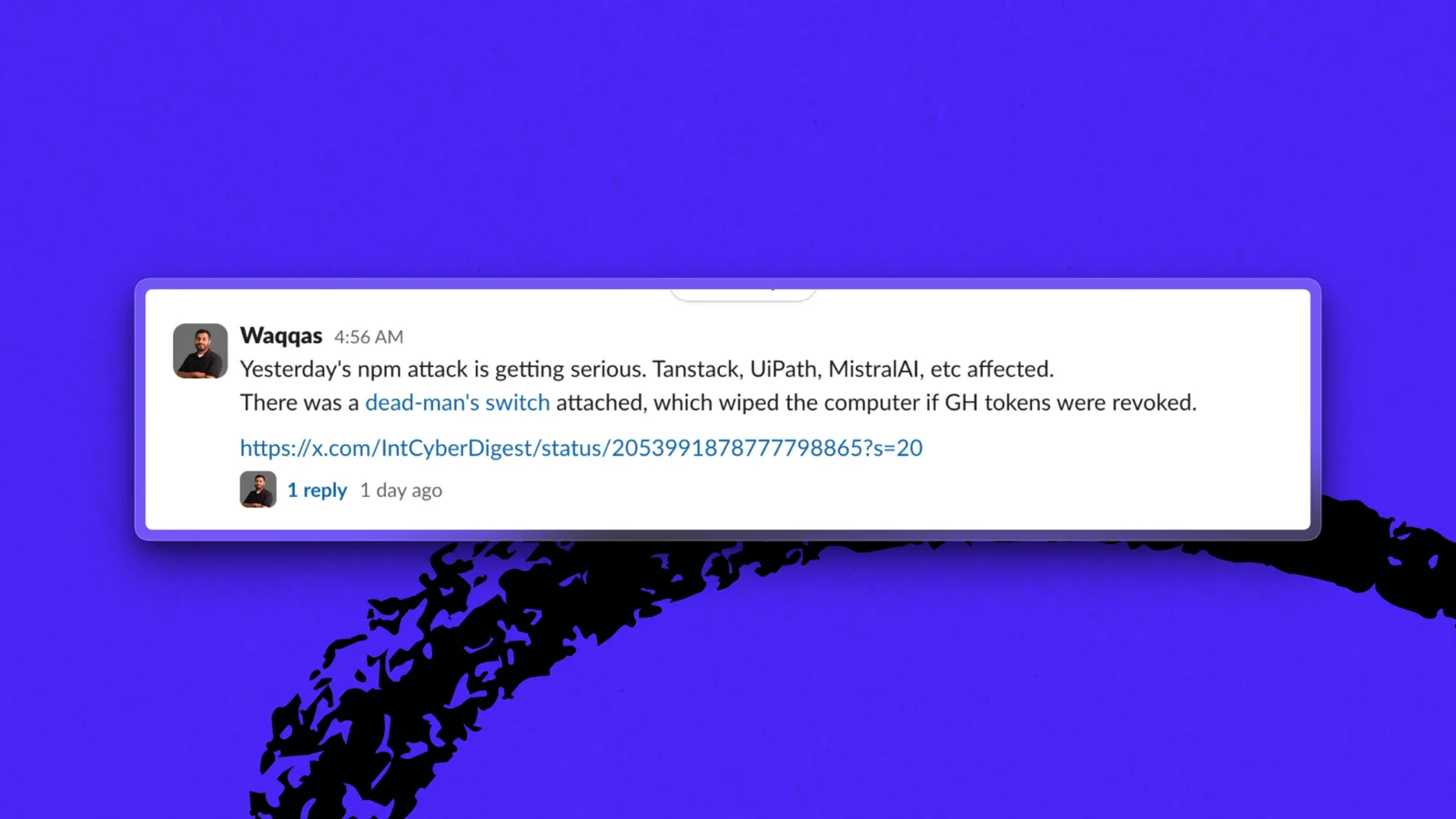 相同的攻击策略蔓延到了与 Mistral 和 UiPath 相关的软件包。(图片由 Waqqas Mir 提供)
相同的攻击策略蔓延到了与 Mistral 和 UiPath 相关的软件包。(图片由 Waqqas Mir 提供)
攻击者并没有窃取密码,而是提交了一个 Pull Request,诱骗 TanStack 自己的构建系统运行了他们的恶意代码。当 TanStack 发布新版本软件时,其中就包含了旨在窃取云密钥、GitHub 令牌和 npm 访问权限等凭证的恶意软件。研究人员还发现了一个“死亡开关”(dead-man's switch)【补充:一种在特定条件触发后自动执行预设操作的机制,此处指若攻击者失去对系统的控制或发现令牌被撤销,即触发破坏】。紧随 TanStack 事件之后,企业自动化公司 UiPath 和法国模型制造商 Mistral AI 等公司的 npm 软件包也遭到了相同手法的攻击。
这意味着什么:自动构建和发布代码的系统,而非代码本身,成了软件供应链中一个新的脆弱环节。自动发布软件的团队应该维护一个随时可以运行的审计程序(可以是一个 Codex 技能、Claude Code 命令,或其他自动化任务),以便在新漏洞曝光的第一时间,扫描每个仓库中是否存在受影响的软件包,并标记出受影响的部分、可能安全的部分,以及需要人工审查的部分。
关键数据
30%
这是写作工具 Spiral 的用户对 AI 写作痕迹的抱怨,在草稿写作流程中增加了一个“最终润色”(top edit)步骤后,下降的比例。
从四月中旬开始,每当 Spiral 为用户生成内容草稿时,文本都会被发送到一个快速模型——Gemini 2.5 Flash——进行最终润色。这个模型只有一个任务:移除草稿中所有的 AI 痕迹,包括破折号、“这不是 X,而是 Y”式的修辞重构,以及诸如“转变”(shift)、“塑造”(shape)和“深入探讨”(delve)等大语言模型偏爱的词汇。Marcus 会根据匿名的用户反馈,定期更新这份“AI 写作痕迹”清单。“这就像一个众包编辑功能,”他说。
换句话说,对抗“AI 味”最有效的方法,不是让人类重写,而是用一个专门识别并擦除 AI 痕迹的模型来收尾。
Every 内部观察
到底什么是智能体(Agent)?
一个在专用 Mac Mini 上 7x24 小时运行的 OpenClaw 算是智能体。一个 Codex 会话、一个自定义 GPT,或者一个文件夹,也都可以被视为智能体。“它可以是被管理的,可以在云端,也可以在你的电脑上,” Kieran 说,“它有数不清的方式成为一个智能体。”
这种混淆之所以出现,是因为“智能体”这个术语——任何能自主采取行动或执行任务的 AI 系统——涵盖的范围实在太广了。
当几乎所有东西都可以被称为智能体时,更好的问题就变成了:你希望你的智能体做什么? Dan 把这分为两类:与你协作的智能体,以及你向其委派任务的智能体。前者的作用是增强和拓展你的能力;后者的任务则是不出错、不碍事地执行指令。
智能体聚焦: 在 Anthropic 的 Managed Agents 控制台中,Spiral 的智能体拥有自己版本化的配置、记忆存储、自定义工具和凭证,并在 Anthropic 的云环境中运行。正是这个版本化的配置,包括系统提示词,主要决定了智能体的工作方式。
一套简洁、赋予其生命力的指令——这本身也是一个智能体。
核心启示:AI 工具之间的竞争正在从单纯比拼“谁更强”,转向在具体的协作或执行场景中“谁更合适”;同时,随着软件构建流程本身的自动化,我们对安全漏洞的认知也需要从代码本身,延伸到整个自动化交付系统。
Opus 4.7 Reels Us Back In 的发芽报告
材料核心
这期简报把四条看似分散的线索放在了一起:团队对模型体感的回摆、供应链攻击把矛头转向构建系统、产品用额外一道 AI 编辑来清除“AI 味”,以及“agent”这个词被越用越宽。它们共同指向一个更实际的问题:我们评估 AI,不该只问“它强不强”,而该问“它在什么工作环节里最可靠”。
发芽 01:从排行榜转向工作场景
文章里最有价值的,不是对 Opus 4.7 是否“真的变强”的定论,而是 Every 团队描述模型差异的方式:Codex 快、稳、适合编码和知识工作;Opus 4.7 在创意写作、规划、多任务和同步协作里更像资深编辑。这种判断不是来自抽象 benchmark,而是来自真实工作流中的摩擦感。
这意味着团队在选模型时,正在从“押注一个通用最强模型”,转向“按任务类型做分工”。当 Kieran 把 fast mode 设成同步工作的默认模型时,本质上是在把模型能力映射到工作节奏:什么任务要速度,什么任务要思考厚度,什么任务要并行规划。
Aha 瞬间
“模型竞争正在从单点能力比较,转向岗位分工比较。”
发芽 02:CI/CD 本身也成了产品表面
TanStack 这类事件提醒我们,自动化发布链路已经不只是工程内部设施,而是产品可信度的一部分。攻击者不需要直接改你的业务代码,只要能让你的构建和发布系统替他执行动作,最终交付给用户的结果照样会被污染。
对依赖自动发布的团队来说,这会把安全工作的重心往前推一层:不只审依赖版本,也要审“谁能触发哪些自动动作”“哪些令牌会在什么上下文暴露”“出现已知供应链事件时,能否快速扫描所有仓库并定位受影响路径”。文章里建议准备一套随时可运行的审计任务,这点很实用,因为真正需要的不是年终复盘,而是漏洞刚公开时的分钟级响应。
Aha 瞬间
“今天的软件供应链,代码库只是表层,流水线才是新的高价值接口。”
发芽 03:去 AI 味,正在变成独立工序
Spiral 的做法说明了一件很现实的事:越来越多产品不会期待‘一次生成就能直接交付’,而是把生成、修正、润色拆成多个模型工序。这里的 top edit 不是重写观点,而是专门清理某些用户已能稳定感知的不自然表达。
这背后反映的是一种新型产品方法:把“AI 痕迹”当成可持续收集、持续更新的缺陷类型来处理。Marcus 根据匿名反馈维护“AI tells”列表,等于把用户的审美摩擦直接接进写作流水线。它不像传统编辑那样追求统一文风,而更像质量控制环节,专门拦截会让读者出戏的信号。
Aha 瞬间
“未来的 AI 内容产品,竞争力不只来自会写,还来自会在最后一步把不该出现的痕迹删掉。”
你的思考空间
如果模型选择越来越像团队里的岗位分工,那么你的工作流里哪些环节应该固定模型,哪些环节反而应该保留可替换性?
当构建系统和自动发布链路本身成为攻击面时,你的团队是否已经把流水线权限、令牌暴露面和应急审计脚本视作一等公民?
当“去 AI 味”变成独立工序后,内容团队真正积累的核心资产,是否会从提示词转移到那份不断更新的“坏味道清单”?