“16小时AI代理”的迷思
关于AI长期可靠性的新数据刚刚出炉,但根据你看到的图表版本,你可能会认为自主AI已经到来,或者它仍需要数年时间。今天,我们来拆解哪一版研究更值得信赖;此外,Perplexity(困惑指数)分享了他们构建不因时间推移而失效的代理技能的方法;Every的CEO Dan Shipper 将他的钢琴键盘变成了一个由Codex驱动的实时音乐教练;而Gusto联合创始人 Edward Kim 则提醒我们,未来的办公室听起来会更像一个销售大厅。——Kate Lee
信号
全天候工作的AI代理近在咫尺——果真如此吗?
自主AI(Agentic AI)的圣杯,一直是其在长时间范围内的可靠性。你期望一个代理能持续工作数小时,即便上下文衰减、没有人类介入来纠正错误转向,它仍然能保持在正确的轨迹上。METR,一家衡量AI能力的非营利机构,发布了一项更新研究,展示了我们离那个自主化未来还有多远。
网上流传的一张研究图表显示,Anthropic的下一代模型Mythos的早期预览版,直接超越了现有模型和METR基准测试套件能可靠测试的16小时范围——几乎冲破了图表上限。
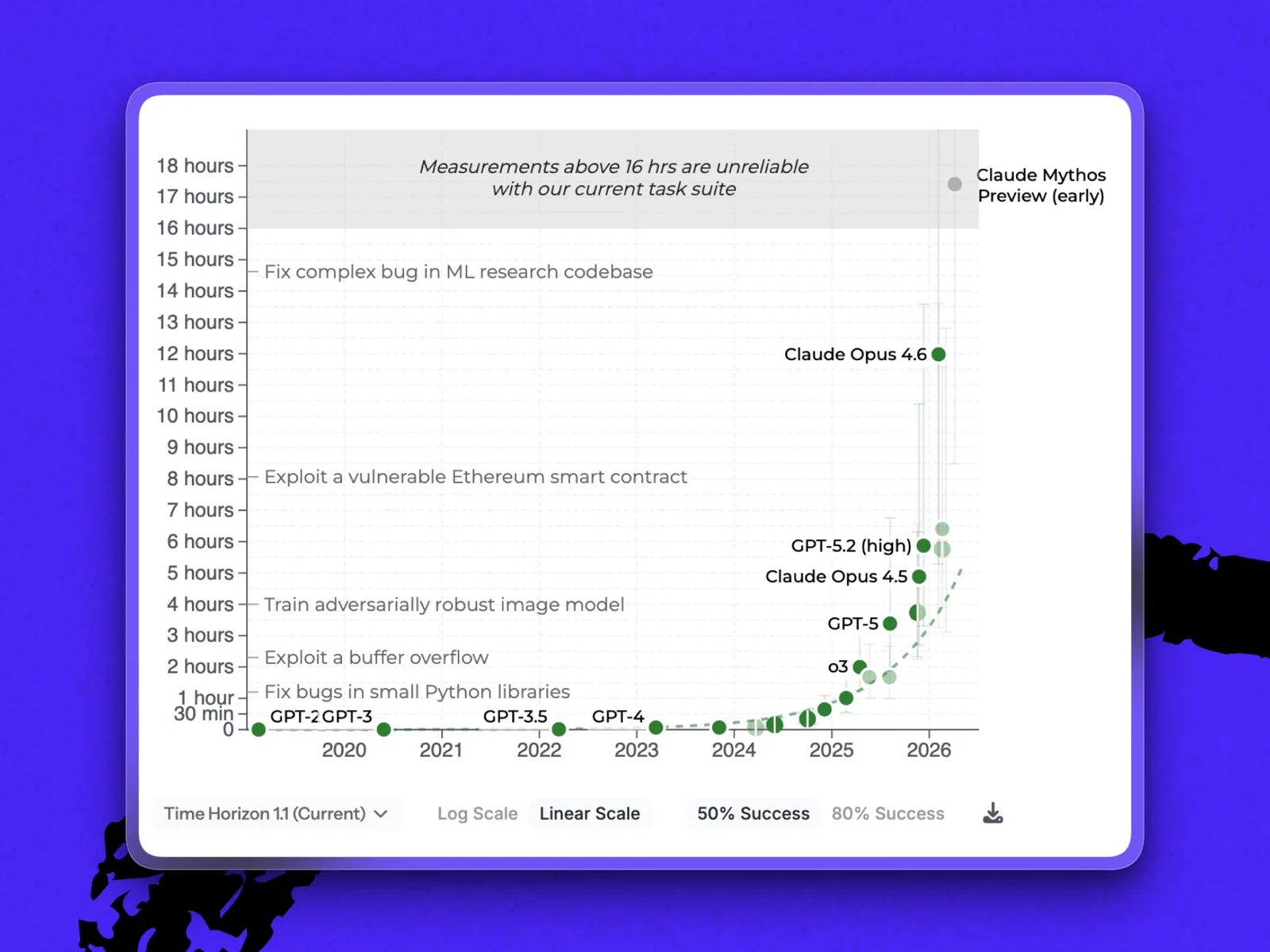 Claude Mythos预览版在50%成功率下达到了METR当前测量范围的边缘。METR提醒,在其现有任务套件下,超过16小时的结果并不可靠。(图片由METR提供)
Claude Mythos预览版在50%成功率下达到了METR当前测量范围的边缘。METR提醒,在其现有任务套件下,超过16小时的结果并不可靠。(图片由METR提供)
然而,需要特别注意的是,一项任务需要耗费多少“人时”,并不等同于模型运行同样任务所花的时间。在METR的基准测试中,“时长”代表的是任务的难度。正如该机构在报告的FAQ中所写:“对于成功完成的任务,AI代理的速度通常是人类的数倍。”
最后这点——“成功完成”的任务——为基准测试增加了另一层复杂性。突破16小时大关的测量是基于50% 的成功率。另一项针对大语言模型(LLM)在80% 可靠性下表现的独立测量显示,Mythos能运行的任务,其难度仅相当于人类三个小时多一点的工作量。这比榜单上最接近的竞争对手Gemini 3.1 Pro(METR目前尚未有Opus 4.7或GPT-5.5的测量数据)有了显著提升。但这张图也把Mythos拉回到了地面。
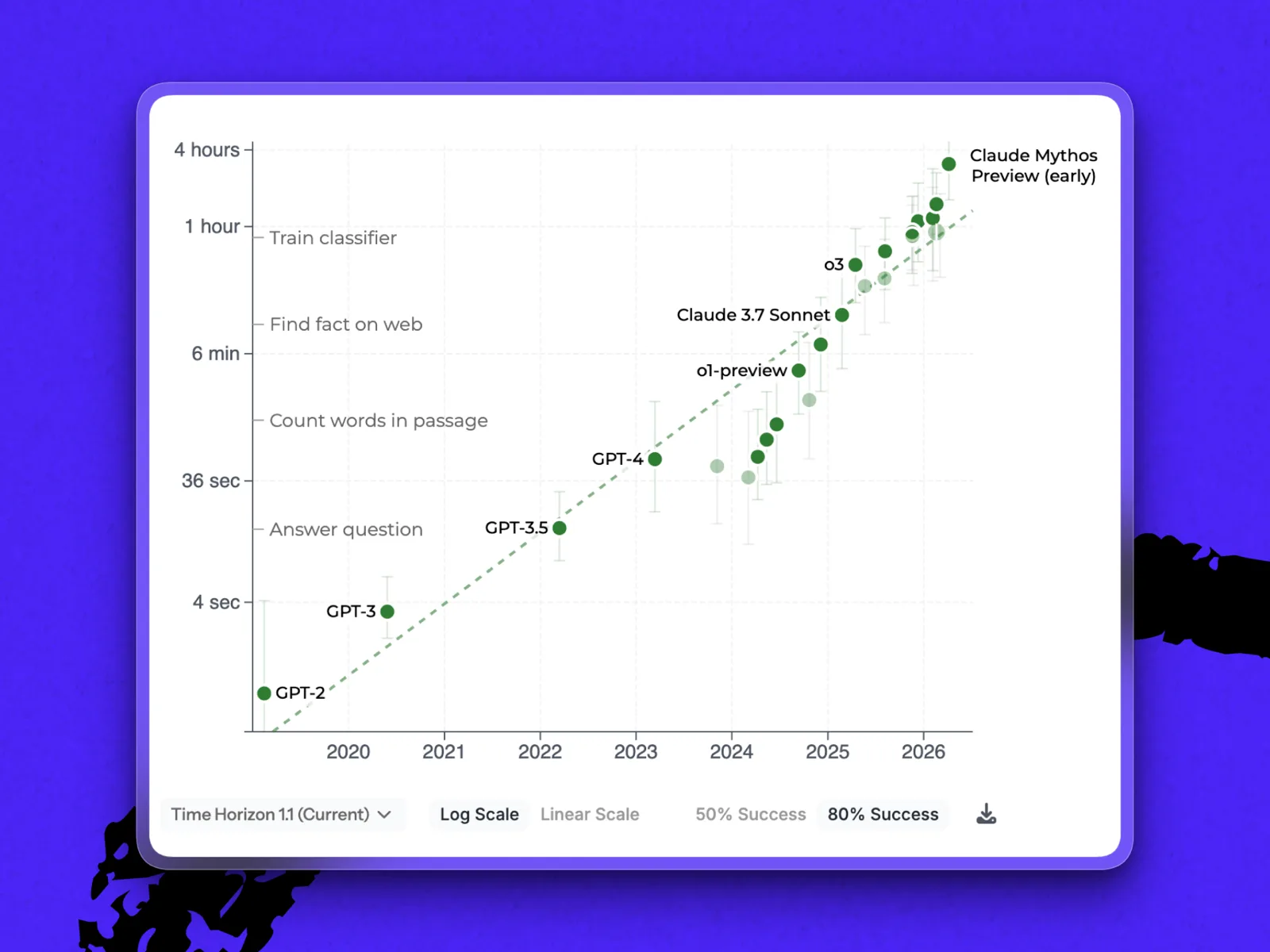 大语言模型在METR的时间范围测试中,以80%成功率完成任务的表现,以对数尺度呈现。(图片由METR提供)
大语言模型在METR的时间范围测试中,以80%成功率完成任务的表现,以对数尺度呈现。(图片由METR提供)
这两件事同时为真:任务时长可以作为衡量难度的有用指标,但基准测试并不等同于现实。Dan 指出:“[它们]衡量的不仅仅是模型自身的能力。它们衡量的是,在人类找到了能让模型能力得以显现的提示词之后,模型所展现出的能力。”
本周行动指南:
找出你运行时间最长的代理任务。 METR教会我们,时长可能是衡量难度的一个很好的近似值。问问自己:你曾让一个代理在无人监管的情况下自主运行的最长时段是多久?如果你不清楚,你就无法延长这个时限。
通过设定目标来延长代理的运行时间。 上个月,OpenAI在Codex中发布了一个新的/goals命令,允许代理在无需人工确认的情况下,跨多个轮次自主追求目标。昨天,Anthropic在最新的Claude Code版本中也引入了一个类似的命令。两者都非常适合那些有明确成功标准的长时间循环任务——这与我们从Claude平台团队那里听到的信息高度一致。今天就试试看。
审计你现有工作循环的有效性。 如果你已经有代理在通宵运行,“你的代理运行了多久?”仍然是一个有用的诊断问题——但问的时候要一并考虑:“它是在什么防护机制下运行的?依赖什么反馈信号?其经过验证的准确率有多高?”
偷师工作流
像Perplexity那样构建你的下一个代理技能
如今,创建一个技能(Skill)相对容易,但创建一个能持续工作的技能却很难。我们都见过这样的场景:某个技能前一天还在正常运行,第二天就可能因为一个错误的请求被触发、在需要时加载失败,或者产出的报告不再像以前那么有用。于是,技能文件被打上补丁,每次代理犯错,文件就变得更长。但没人能确定最新的修改是让情况变好了还是变糟了。
Perplexity,这家正在构建自主研究和浏览工具的AI搜索公司,最近公开了其设计代理技能的方法论。其核心经验是:与其从技能本身开始,不如从编写测试开始。以下是该文章的要点:
- 先写评估用例。 从生产环境的查询、已知的失败案例和边缘情况中抽取5到10个案例。要包括反面例子——即那些不应该激活此技能的查询。
- 像人类一样编写触发短语。 从“当……时加载”开始,并使用用户的语言。Perplexity的例子:与其用“监控拉取请求(monitors pull requests)”,不如试试“照看这个PR”、“盯着CI”或“确保这个能合入”。这样,团队成员就无需使用特定的命令或技术短语来触发技能。
- 用原则而非步骤来编写技能主体。 模型已经懂得具体命令,它需要的是如何应用这些命令的指导。例如,与其详细列出签出新分支、精选(cherry-pick)要编辑的文件、检查冲突等具体步骤,Perplexity建议使用这样的指令:“将提交精选到一个干净的分支上。解决冲突时,保留原始意图。”
- 将失败模式固化为教训。 当代理在生产环境中失败时,将失败模式写入技能文件。这个错误就成了一条避免未来重蹈覆辙的长效指令。
- 严格编辑指令。 每增加一行时都要问自己:“没有这一行,代理会出错吗?”如果不会,就删掉它。每多一行都会增加上下文成本。
本周尝试一下: 选择一个你的团队想改进的技能。写出10个测试用例——5个是它应该处理的,5个是它应该拒绝或转交给其他处理流程的。让当前的技能去跑这些测试。测试结果中暴露出的差距,就是你的待办清单。
探讨
“未来的办公室听起来会更像一个销售大厅。”
— Edward Kim ,Gusto联合创始人,在《华尔街日报》上的发言
本周《华尔街日报》一篇关于AI语音输入工具进入职场的文章,将语音提示和写作视为一种礼仪问题——这个角度表明,事物变化越多,其本质越保持不变。
每一种新的工作界面最终都会创造出新的礼仪规范。电子邮件催生了“回复全部”的政治学,Slack催生了通知的政治学。语音AI即将催生“环境音”的政治学:你何时可以与计算机交谈、音量多大、以及在谁身边可以这样做。这对爱管闲事的办公室邻居来说是个好消息,但对我们其他人来说,这又多了一个诅咒开放式办公室布局的理由。
Every内部动态
本周,Thinking Machines Lab和OpenAI都宣布了对同一种未来的押注:AI将实时观察并作出反应,而非等待轮到自己发言。OpenAI推出了Realtime-2语音模型;Thinking Machines则预览了一个能同时观看视频和音频的交互模型。
在我们所有人都在等待这些实验室的愿景如何落地时,Dan用Codex为自己临时拼凑了一个类似的版本。
上周六,他将自己的MIDI键盘——一种能将音符转化为计算机可读数据的键盘——连接到笔记本电脑上,打开Codex,要求它构建一个钢琴应用。这个应用要能识别他弹奏的和弦,然后持续观察并在他练习时进行指导。这种模式可以推广到任何实时媒介:在文档中写作、在平板上绘画、在手机前做硬拉。这也正是像Meta的AR/VR眼镜或Apple Vision Pro这类硬件所蕴含的承诺:AI能看到你在做什么,并以有用的方式做出回应。
你也可以这样做:
- 找到输入管道。 乐器用MIDI。写作或设计用屏幕捕捉。绘画或动作捕捉用摄像头加一个视觉模型。语言学习用麦克风。
- 让代理来构建观察者应用。 根据你希望被指导的方式,让Codex(或Claude Code)来编写应用。(例如,告诉它一次只提供一条反馈,或者专注于你技术的某一特定方面而忽略其他。)
- 在使用中不断调整反馈。 最初的回应可能很笼统(“很好的和弦进行”)。告诉你的观察者什么有用、什么没用——“只标记错误的音符”、“忽略强弱变化”、“等我弹完一个乐句再打断我”。
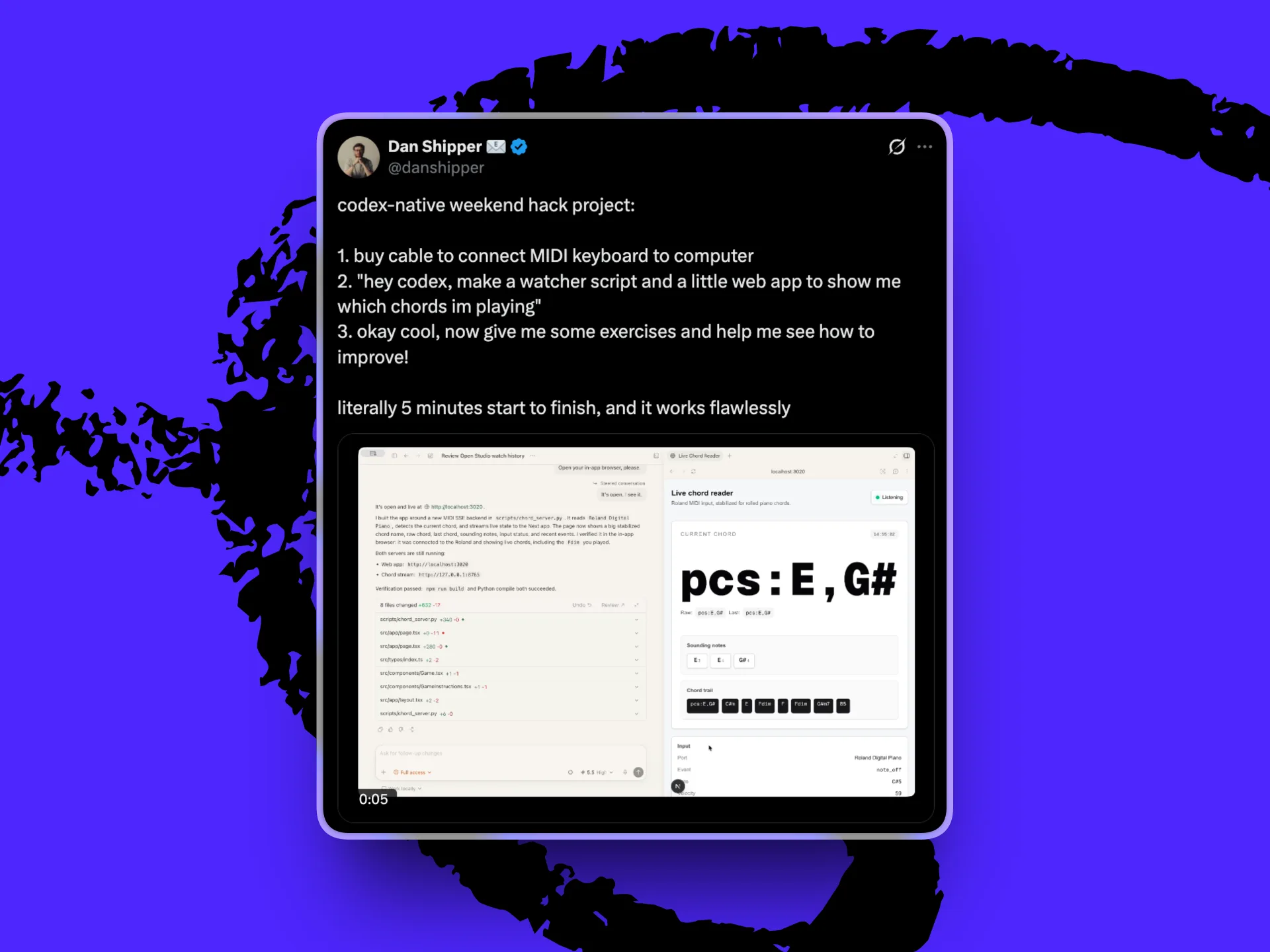 Dan基于Codex的原生钢琴教练设置,教练应用在应用内浏览器中打开。(图片由Dan Shipper提供)
Dan基于Codex的原生钢琴教练设置,教练应用在应用内浏览器中打开。(图片由Dan Shipper提供)
本周尝试一下: 选择一项你想精进的技能。打开你练习时所用的媒介。花一个晚上,和你的编程代理一起,构建一个你能做到的最简观察者——输入信息,输出反馈。不知不觉中,你就会拥有一个可以随叫随到的私人教练。
核心启示:METR的数据揭示了一个双面现实,而Perplexity的实践则给出了应对之道:当前AI的长期自主能力,其上限不仅受限于模型本身的可靠性,更取决于我们为它设定的成功标准以及我们持续迭代、测试并固化教训的系统性工程能力。

The Fallacy of the 16-hour Agent 的发芽报告
材料核心
这篇文章剖析了 METR 基准测试中"16 小时任务时长"数据被误读的现象——这一数字代表任务难度而非模型实际运行速度,且在不同成功率标准下(50% vs 80%)模型表现差异巨大。文章同时提供了 Perplexity 的设计实践和 Dan Shipper 的钢琴教练实验,从评测、构建和交互三个层面探讨了当前 Agent 能力的真实边界。
发芽 01:测量幻觉——当数字比模型更不可靠
种子
材料揭示了评测领域的一个深层悖论:最容易被传播的数字(16 小时 Agent)恰恰是最不可靠的。这不是模型的问题,而是测量文化的集体幻觉——我们用方便的数字替代真实的复杂性,然后根据这个数字制定策略。
1975 年,经济学家查尔斯·古德哈特(Charles Goodhart)提出了后来被称为"古德哈特定律"的观察:当一个指标成为政策目标时,它就不再是一个好指标。METR 基准测试面临的正是古德哈特式的困境。METR 自己明确写道,时长代表的是人类完成任务的难度,而非 AI 运行该任务的实际耗时,且 16 小时以上数据"unreliable"。但社交网络上的传播剥离了所有这些警告,只剩下"Mythos 突破 16 小时"的叙事。
这里面藏着两条岔路。一条走向自我欺骗:把 50% 成功率当作够用,忽略从三小时到十六小时的鸿沟其实只是置信度从 80% 跌落到 50% 的副产品。另一条走向测量虚无主义:"基准测试不能代表现实,所以我们不看了。"
Perplexity 的做法提供了一条中间道路。他们不为技能写评测,而是让评测定义技能——从真实查询中抽取 5 到 10 个案例,包括边界情况和负面案例,先建立评测标准。这本质上是在对抗古德哈特定律:不是找一个更完美的全局指标,而是把"什么是好"的定义权从抽象的基准交还给具体的任务场景。
Aha 瞬间
"当 16 小时任务时长成为头条时,真正被测量的不是模型能力,而是我们的注意力——我们发现,人类在压缩复杂信息这件事上,比当前的 AI 更不靠谱。"
发芽 02:从原则到程序——指令的退化曲线
种子
Perplexity 的方法论中有一个容易被忽略的细节:"Write the body in principles, not procedures."(用原则写指令主体,而非步骤清单。)这看似是提示工程技巧,实则揭示了一个更深的组织哲学:系统的可靠性不是靠补充规则维系的,而是靠原则让模型自己推导。
这个洞见在历史上有一个有趣的类比。1980 年代,丰田生产方式(TPS)开始被西方企业学习。很多公司模仿丰田的看板、安灯系统、准时化生产,写成厚厚的手册——结果运行不起来。后来研究者发现,丰田工厂的成功不在于工人遵守规则,而在于工人理解原则。丰田的前工程经理大野耐一不是告诉工人"遇到问题就拉绳",而是让他们理解"暴露问题比生产速度更重要"的原则,然后工人自己推导出拉绳这个动作。
AI 技能的维护面临着同样的张力。文章描述了一个熟悉的现象:Agent 出错,于是技能文件被修补,不断变长。但没人知道最新的一次编辑是修复还是退化。Perplexity 的解决方案是反直觉的——不把失败的补救措施加入步骤清单,而是把"失败模式"写成一条原则:"Cherry-pick the commit onto a clean branch. Resolve conflicts preserving intent."这是一个可以从内部推导的原则,而不是一条需要死记硬背的规则。
这里还有一个隐含的批评:我们对 AI 的信任危机,很大程度源于我们用"程序思维"管理一个"原则性系统"。模型本身更擅长理解意图和边界条件,但人类总想把所有可能出错的地方都写成 if-then。Dan Shipper 的钢琴教练正好佐证了这一点——他不是给 Codex 写一套完整的音乐教学法,而是告诉它"只提醒弹错的音""让我弹完一个乐句再打断"。Agent 不需要知道所有音乐理论,它只需要一条足够好的原则来引导判断。
Aha 瞬间
"Perplexity 的实践告诉我们一个反直觉的真相:最可靠的 Agent 不是被最多指令约束的那个,而是被最少但最根本的原则指引的那个——就像丰田工人不需要 500 页的操作手册,只需要一个'暴露问题'的信念。"
发芽 03:无意识的 Agent——重新定义"自主"
种子
材料开头描绘了长时自主 Agent 的愿景——"hand a task and trust to still be on the right thread hours later"。但这里有另一种可能性:最好的长时 Agent 可能不是你"信任"的那个,而是你"遗忘"的那个。
2007 年,神经科学家 David Eagleman 做过一个著名的实验:让受试者在看屏幕时按下一个按钮,同时记录大脑活动。他发现受试者在"意识到自己做出决定"之前 300 毫秒,大脑已经在准备按下按钮的动作。意识不是决策的发起者,而是决策的事后解释者。
Agent 的自主性或许也应该这样重新理解。当 Dan Shipper 的钢琴教练在实时观看他的演奏并给出反馈时,这个 Agent 不是在"被信任"——Dan 不会随时检查它的状态,问它"你还在追踪和弦吗?"Agent 进入了 Dan 的练习流,成为一个隐形教练。这和 Edward Kim 说的"未来办公室像销售大厅"形成了意外的呼应:当语音 AI 无处不在,AI 不再是意识焦点,而是和键盘鼠标一样退入注意力的边缘。
材料中 METR 的图表之所以引发误解,也和这种认知错位有关。我们用"16 小时等于自主"这个公式,是假设 Agent 是一个有意识的打工者,需要人类保持信任。但 Dan 的实验和 Thinking Machines Lab 的实时交互模型指向的是另一种未来:Agent 不再是被漫长信任链拴住的任务执行者,而是一种环境——你弹琴,它听着;你写作,它看着。你不需要"信任它 16 小时",你需要的是它在你注意力的间隙里恰好出现。
Aha 瞬间
"人类真正需要的不是可信任 16 小时的 Agent,而是像呼吸一样无需被'信任'的 Agent——它只是在适当的时候,递给你正确的东西。"
你的思考空间
如果一个基准测试在超过 16 小时后"unreliable",我们是否应该停止追求更长的任务时长,转而追求在已知边界内更高的可靠性?还是会因此错过真正的突破点?
当 Perplexity 说"每多一行指令就增加上下文成本"时,这和经济学家说的"边际成本递增"是否指向同一个底层逻辑?如果指令质量和可靠性之间的关系也是非线性的,那么"最小可行指令集"应该是多少?
Dan Shipper 用 MIDI 键盘构建了一个实时反馈的教练。如果同样的模式应用到管理者对团队的反馈上——不是等周报,而是实时"看到"团队的产出并给出一条原则性建议——这会让管理变得更好还是更糟?
如果语音 AI 让未来的办公室变得像销售大厅一样嘈杂,那么"安静的专注工作"会成为新的奢侈品吗?历史上,开放式办公室的普及也经历过类似的阻力,最终是耳机创造了私人声场——那么,AI 时代的"降噪耳机"会是什么形态?